笔者最近思考如何编写高效的爬虫; 而在编写高效爬虫的时候,有一个必需解决的问题就是: url 的去重,即如何判别 url 是否已经被爬取,如果被爬取,那就不要重复爬取。
一般如果需要爬取的网站不是非常庞大的话,使用Python 内置的 set 就可以实现去重了,但是使用 set 内存利用率不高,此外对于那些不像Python 那样用 hash 实现的 set 而言,时间复杂度是 log(N),实在难说高效。
1 Bloom Filter
那么如何实现高效的去重呢? 笔者查阅资料之后得知:使用布隆过滤器 (Bloom Filter).
布隆过滤器可以用于快速检索一个元素是否在一个集合中。布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数(Hash函数)。
而一般的判断一个元素是否在一个集合里面的做法是:用需要判断的元素和集合中的元素进行比较,一般的数据结构,例如链表,树,都是这么实现的。
缺点是:随着集合元素的增多,需要比较的元素也增多,检索速度就越来越慢。
而使用布隆过滤器判重可以实现常数级的时间复杂度(检索时间不随元素增长而增加).那么布隆过滤器又是怎样实现的呢
1.1 布隆过滤器实现原理
一个Bloom Filter是基于一个m位的位向量(Bit Vector),这些位向量的初始值为0, 并且有一系列的 hash 函数,hash 函数值域为1-m.在下面例子中,是15位的位向量,初始值为0以空白表示,为1以颜色填充
{kind=link}
现在有两个简单的 hash 函数:fnv,murmur.现在我输入一个字符串 “whatever” ,然后分别使用两个 hash 函数对 “whatever” 进行散列计算并且映射到上面的位向量。
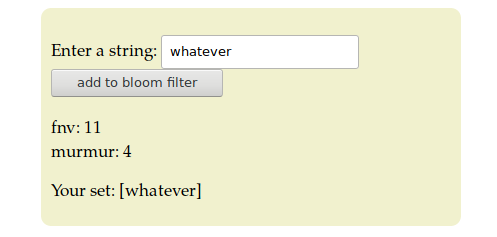{kind=link}
可知,使用 fnv 函数计算出的 hash 值是11,使用 murmur 函数计算出的 hash 值是4. 然后映射到位向量上:
{kind=link}
如果下一次,笔者要判断 whatever 是否在字符串中,只需使用 fnv 和 murmur 两个 hash 函数对 whatever 进行散列值计算,然后与位向量做 “与运算”,如果结果为0, 那么说明 whatever 是不在集合中的,因为同样的元素使用同一个 hash 函数产生的值每次都是相同的,不相同就说明不是同一个元素。
但是如果 “与运算” 的结果为1,是否可以说明 whatever 就在集合中呢?其实上是不能100% 确定的,因为 hash 函数存在散列冲突现象 (即两个散列值相同,但两个输入值是不同的), 所以布隆过滤器只能说"我可以说这个元素我在集合中是看见过滴,只是我有一定的不确定性".
当你在分配的内存足够大之后,不确定性会变得很小很小。
你可以看到布隆过滤器可以有效利用内存实现常数级的判重任务,但是鱼和熊掌不可得兼,付出的代价就是一定的误判 (机率很小),所以本质上,布隆过滤器是 “概率数据结构 (probabilistic data structure)”.
这个就是布隆过滤器的基本原理。当然,位向量不会只是15位,hash函数也不会仅是两个简单的函数. 这只是简化枝节,为了清晰解述原理而已。
2 Python BloomFilter
算法都是为了实际问题服务的,又回到爬虫这个话题上。在了解布隆过滤器原理之后,可以很容易地实现自己的布隆过滤器,但是想要实现一个高效健壮的布隆过滤器就需要比较多的功夫了,因为需要考虑的问题略多。
幸好,得益Python 强大的社区,已经有Python BloomFilter 的库。一个文档中的简单例子:
| |
结果为 True
3 总结
原理就说得差不多了,要想对布隆过滤器有更深的认识,还需要更多的实战。多写,多思考。 Enjoy Python,Enjoy Crawler :)
4 参考
 公号同步更新,欢迎关注👻
公号同步更新,欢迎关注👻