我最近编写了两只京东商品和评论的分布式爬虫来进行数据分析,现在就来分享一下。
1 爬取策略
众所周知,爬虫比较难爬取的就是动态生成的网页,因为需要解析 JS, 其中比较典型的例子就是淘宝,天猫,京东,QQ 空间等。
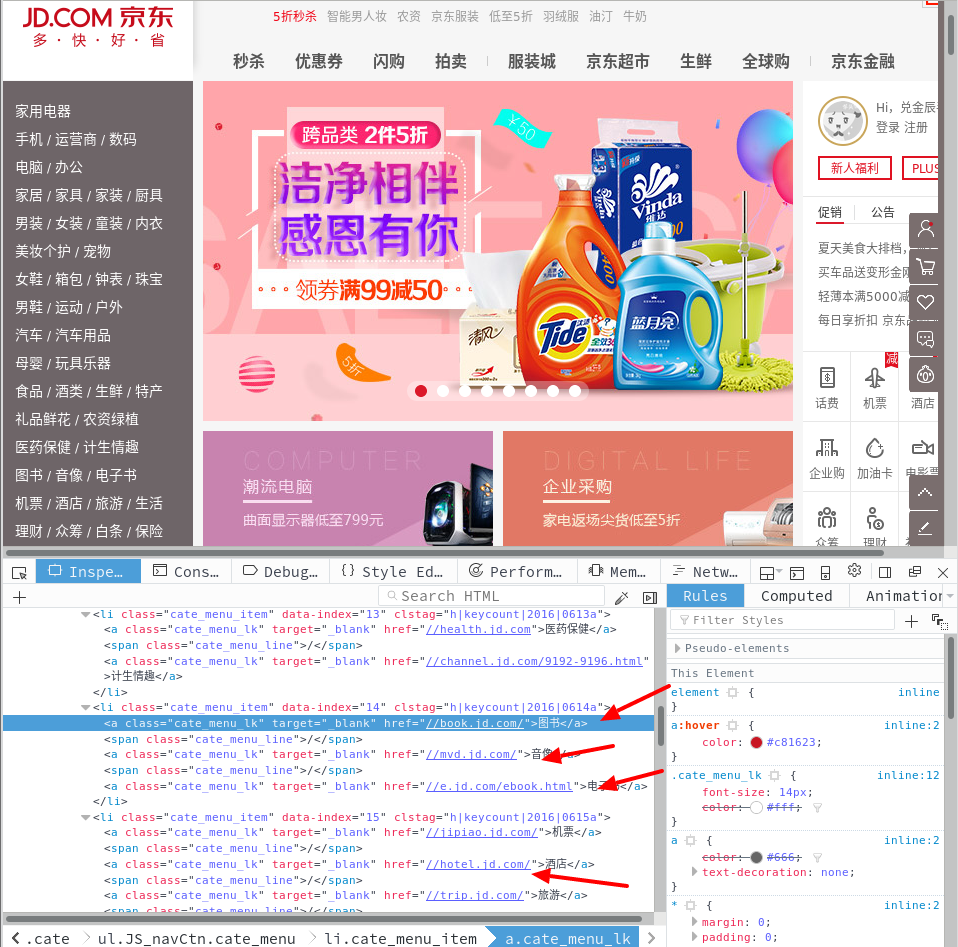
所以在我爬取京东网站的时候,首先需要确定的就是爬取策略。因为我想要爬取的是商品的信息以及相应的评论,并没有爬取特定的商品的需求。所以在分析京东的网页的 url 的时候, 决定使用类似全站爬取的策略。 分析如图:
{kind=link}
可以看出,京东不同的商品类别是对应不同的子域名的,例如 book 对应的是图书, mvd 对应的是音像, shouji 对应的是手机等。
因为我使用的是获取 <a href> 标签里面的 url 值,然后迭代爬取的策略。所以要把爬取的 url 限定在域名为jd.com 范围内,不然就有可能会出现无限广度。
此外,有相当多的页面是不会包含商品信息的;例如: help.jd.com, doc.jd.com 等,因此使用 jd.com 这个域名范围实在太大了,所以把所需的子域名都添加到一个 list :
| |
2 提取数据
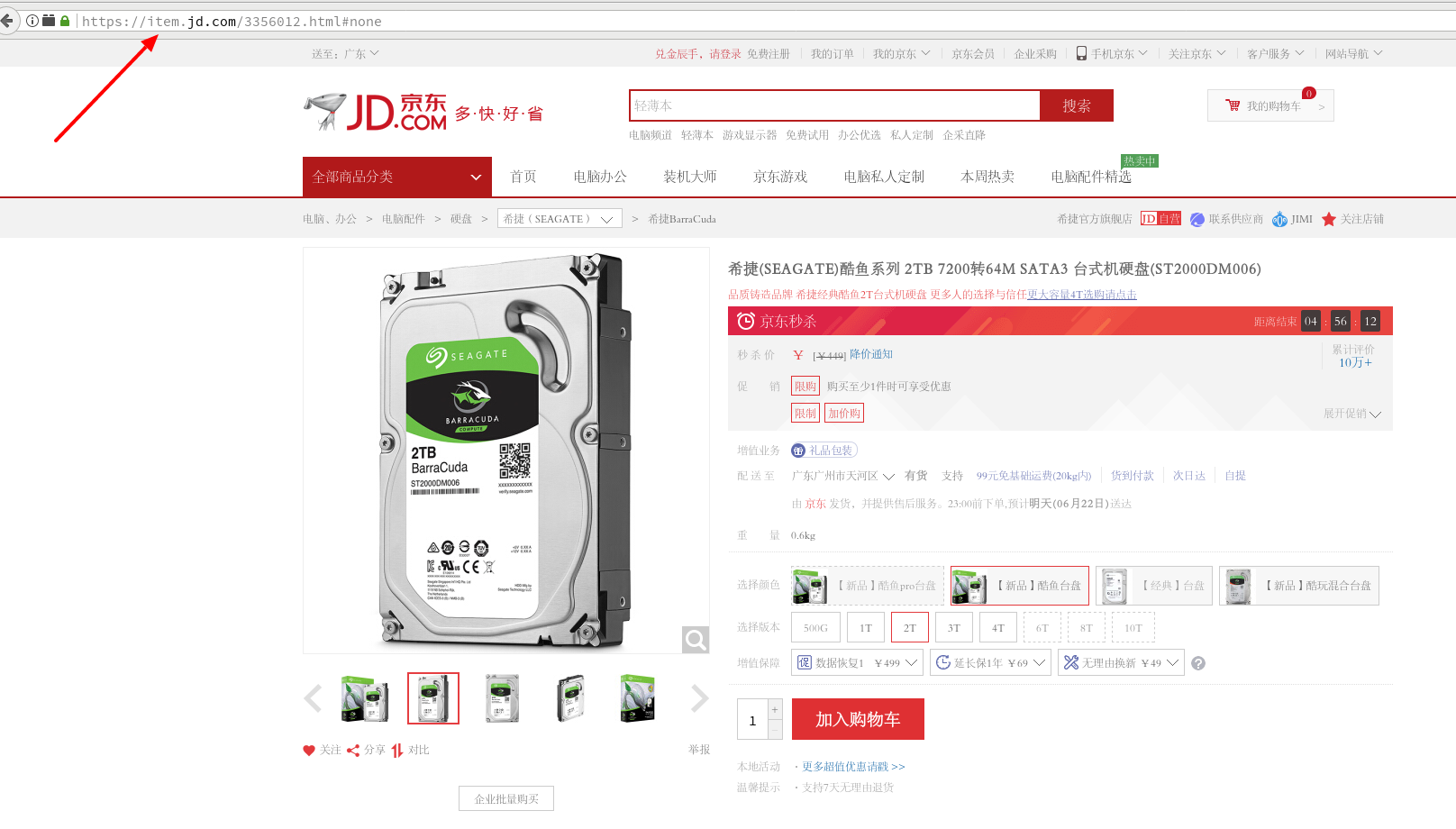
在确定了爬取策略之后,爬虫就可以不断地进行工作了。那么爬虫怎么知道什么时候才是商品信息的页面呢?再来分析一下京东的商品页面:
{kind=link}
从上面的信息可以看出,每个商品的页面都是以 item.jd.com/xxxxxxx.html 的形式存 在的;而 xxxxxxx 就是该商品的 sku-id. 所以只需对 url 进行解析,子域名为 item 即商品页面,就可以进行爬取。
页面提取使用 Xpath 即可,也无需赘言。不过,需要注 意的是对商品而言,非常重要的价格就不是可以通过爬取 HTML 页面得到的。
因为价格是经常变动的,所以是异步向后台请求的。对于这些异步请求的数据,打开控制台,然后刷新,就可以看到一堆的 JS 文件,然后寻找相应的请求带有 “money 或者price” 之类关 键字的 JS 文件,应该就能找到。
如果还没办法找出来的话,Firefox 上有一个 user-agent-switcher 的扩展,然后通过这个扩展把自己的浏览器伪装成 IE6, 相信所有
花俏的 JS 都会没了, 只剩下那些不可或缺的 JS, 这样结果应该一目了然了,这么看来 IE6 还是有用滴。最终找到的URL 如下
https://p.3.cn/prices/mgets?callback=jQuery6646724&type=1&area=19_1601_3633_0.137875165&pdtk=9D4RIAHY317A3bZnQNapD7ip5Dg%252F6NXiIXt90Ahk0if2Yyh39PZQCuDBlhN%252FxOch3MpwWpHICu4P%250AVcgcOm11GQ%253D%253D&pduid=14966417675252009727775&pdpin=%25E5%2585%2591%25E9%2587%2591%25E8%25BE%25B0%25E6%2589%258B&pdbp=0&skuIds=J_3356012&ext=10000000&source=item-pc
不得不说,URL 实在是太长了。
根据经验,大部分的参数应该都是没什么用的,应该可以去掉的,所以在浏览器就一个个参数去掉,然后试试请求是否成功,如果成功,说明此参数无关重要,最后简化成: http://p.3.cn/prices/mgets?pduid={}&skuIds=J_{} sku_id 即商品页面的 URL中包含的数字,而 pduid 则是一随机整数而已,用
random.randint(1, 100000000) 函数解决。
3 商品评论
商品的评论也是以 sku-id 为参数通过异步的方式进行请求的,构造请求的方法跟价格类 似,也不需过多赘述。
只是想要吐嘈一下的是,京东的评论是只能一页页向后翻的,不能跳转。还有一点就是,即使某样商品有 10+w 条评论,最多也只是返回 100页的数据。 略坑
4 反爬虫策略
商品的爬取策略以及提取策略都确定了,一只爬虫就基本成型了。
但是一般比较大型的网站都有反爬虫措施的。
所以道高一尺,魔高一丈,爬虫也要有对应的反反爬虫策略
4.1 禁用 cookie
通过禁用 cookie, 服务器就无法根据 cookie 判断出爬虫是否访问过网站
4.2 轮转 user-agent
一般的爬虫都会使用浏览器的 user-agent 来模拟浏览器以欺骗服务器 (当然,如果你是一只什么 user-agent都不用耿直的小爬虫,我也无话可说).
为了提高突破反爬虫策略的成功率,可以定义多个 user-agent, 然后每次请求都随机选择 user-agent。
4.3 伪装成搜索引擎
要说最著名的爬虫是谁?肯定是搜索引擎,它本质上也是爬虫,而且是非常强大的爬虫。
而且这些爬虫可以光明正大地去爬取各式网站,相信各式网站也很乐意被它爬。
那么, 现在可以通过修改 user-agent 伪装成搜索引擎,然后再结合上面的轮转 user-agent,
伪装成各式搜索引擎:
| |
4.4 代理 IP
虽说可以伪装成搜索引擎,但是因为 http 请求是建立在三次握手之上的,爬虫的 IP 还是会被记录下来的,如果同一个 IP 访问得太频繁,那基本就可以确定是一只爬虫了,然后就把它的 IP 封掉,温和一点的就会叫你输入验证码,不然就返回 403.
对待这种情况,就需要使用代理 IP 了。
只是代理 IP 都有不同程度的延迟,并且免费的 IP 大多不能用,所以这是不得而为之了
5 扩展成分布式爬虫
一台机器的爬虫可能爬取一个网站可能需要 100 天,而且带宽也到达瓶颈了,那么是否可以提高爬取效率呢?
那就用 100台机器,1天应该就能爬取完 (当然,现实并非如此美好).
这个就涉及到分布式的爬虫的问题。而不同的分布式爬虫有不同的实现方法,而我选择了 scrapy 和 redis 整合的 scrapy-redis 来实现分布式,URL 的去重以及调度都有了相应的实现了,也无需额外的操心
6 爬虫监控
既然爬虫从单机变成了分布式,新的问题随之而来:如何监控分布式爬虫呢?在单机的时候,最简单的监控 – 直接将爬虫的日志信息输出到终端即可。
但是对于分布式爬虫,这样的做法显然不现实。我最终选择使用 graphite 这个监控工具。
6.1 scrapy-graphite
参考 Github上 distributed_crawler 的代码,将单机版本的 scrapy-graphite 扩展成基于分布式的 graphite 监控程序,并且实现对 python3 的支持。
6.2 docker
但是 graphite 只是支持 python2, 并且安装过程很麻烦,我在折腾大半天后都无法安装成功,实在有点沮丧。最后想起了伟大的 docker, 并且直接找到已经打包好的image. 数行命令即解决所有的安装问题,不得不说:docker, 你值得拥有。运行截图:
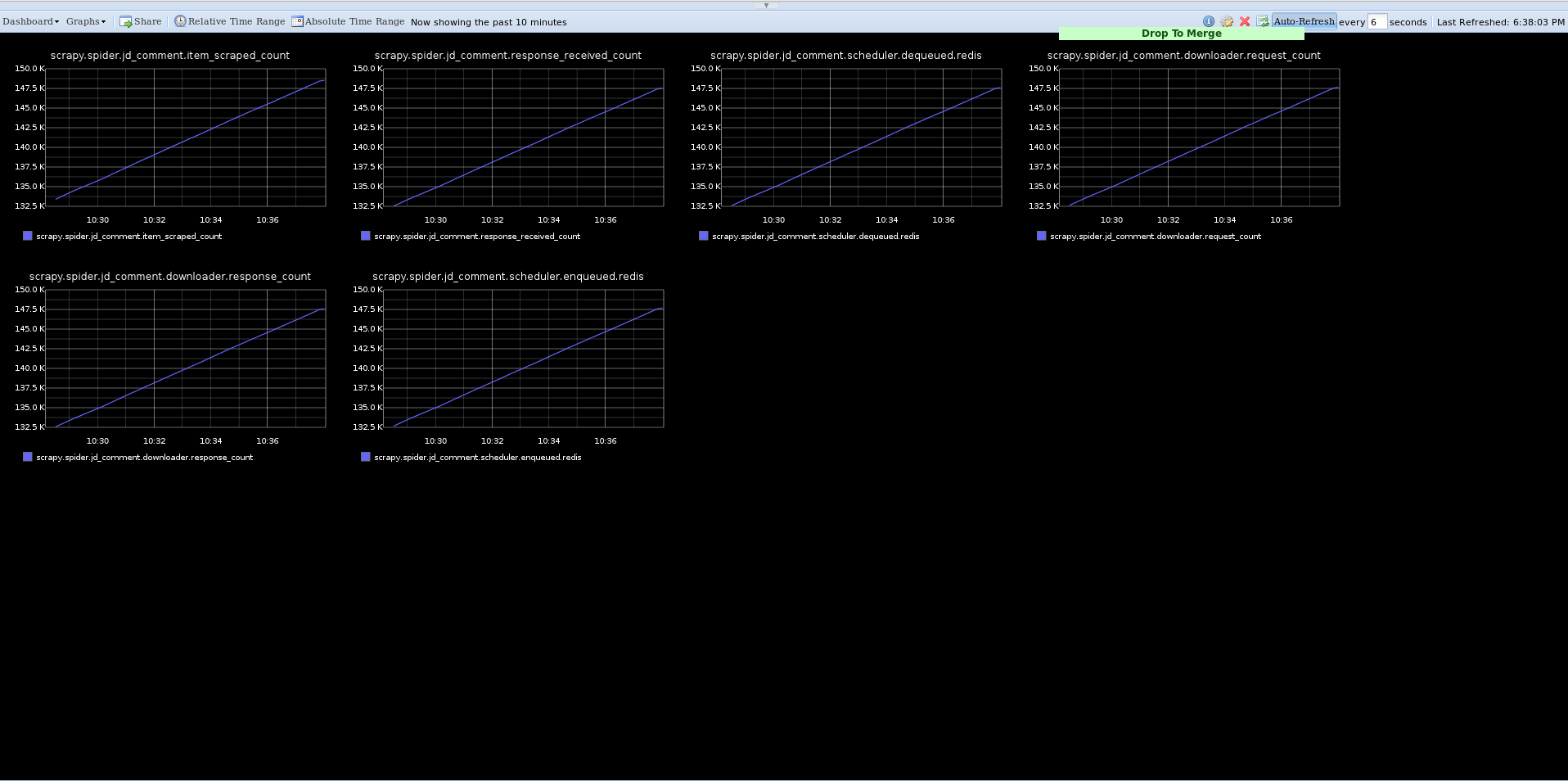{kind=link}
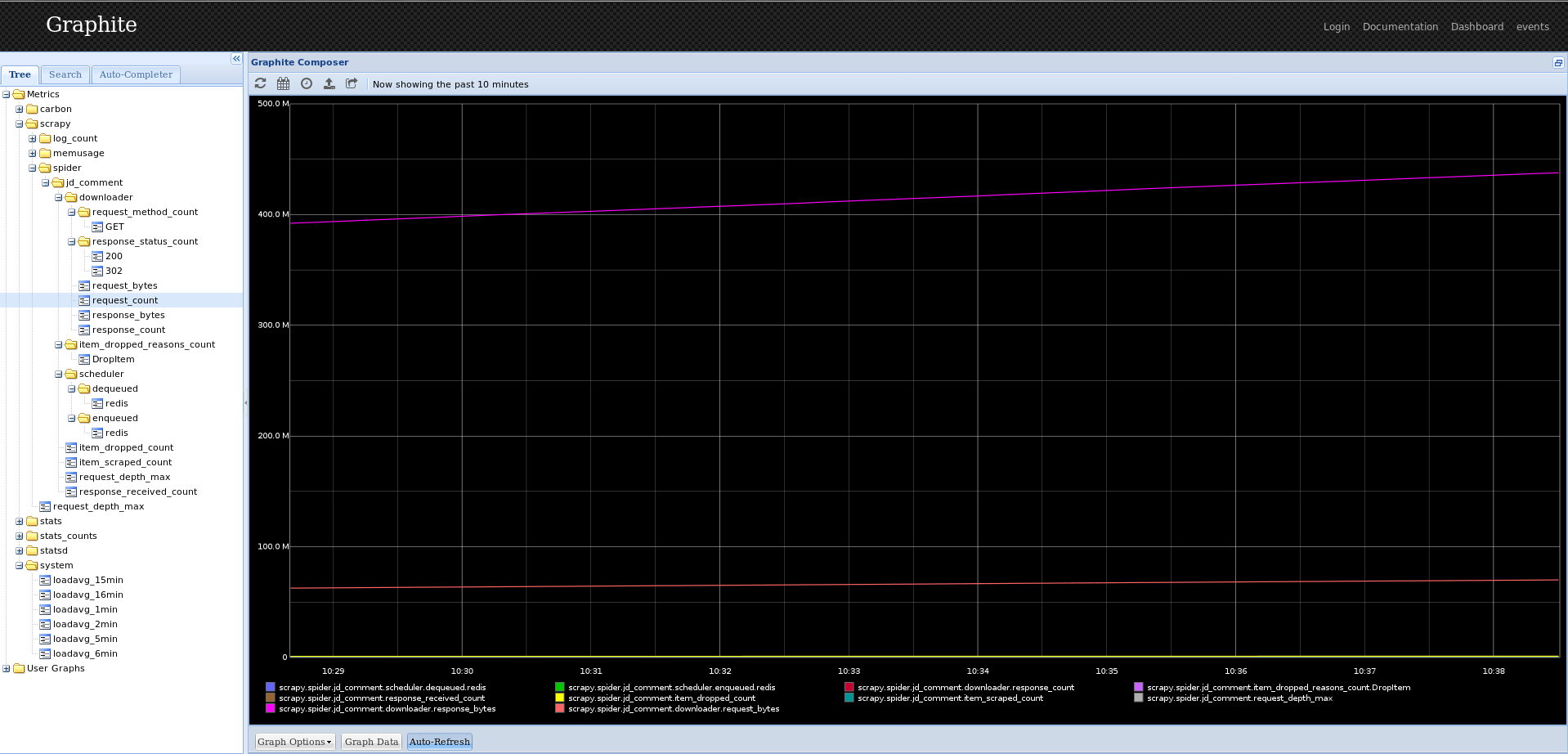{kind=link}
7 爬虫拆分
本来爬取商品信息的爬虫和爬取评论的爬虫都是同一只爬虫,但是后来发现,再不使用代理 IP 的情况下,爬取到 150000 条商品信息的时候,需要输入验证码。
但是爬取商品评论的爬虫并不存在被反爬策略限制的情况。所以我将爬虫拆分成两只爬虫,即使无法爬取商品信息的时候,还可以爬取商品的评论信息。
8 小结
在爬取一天之后,爬虫成果:
8.1 评论
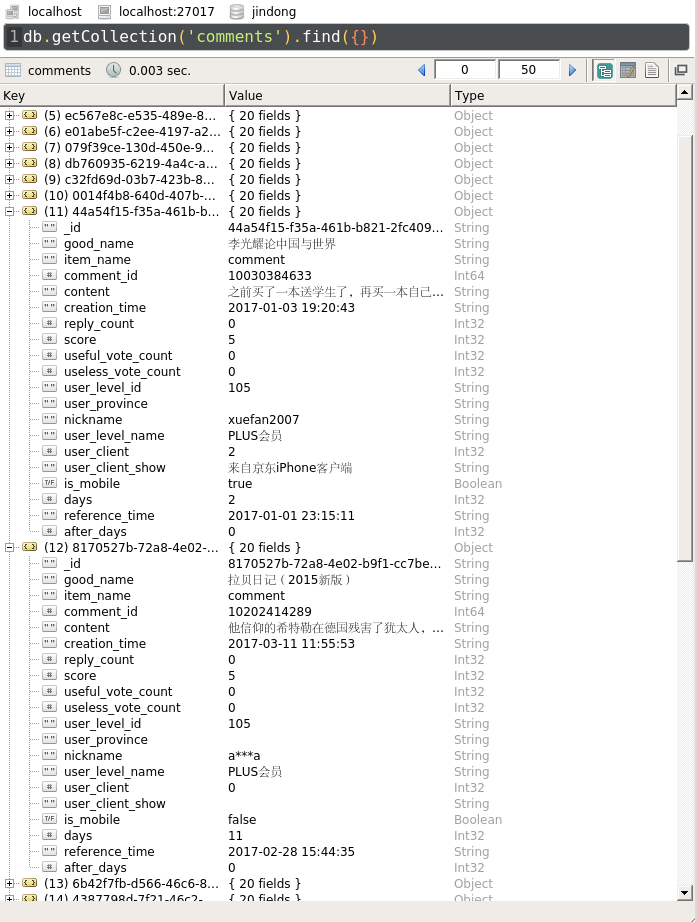{kind=link}
8.2 评论总结
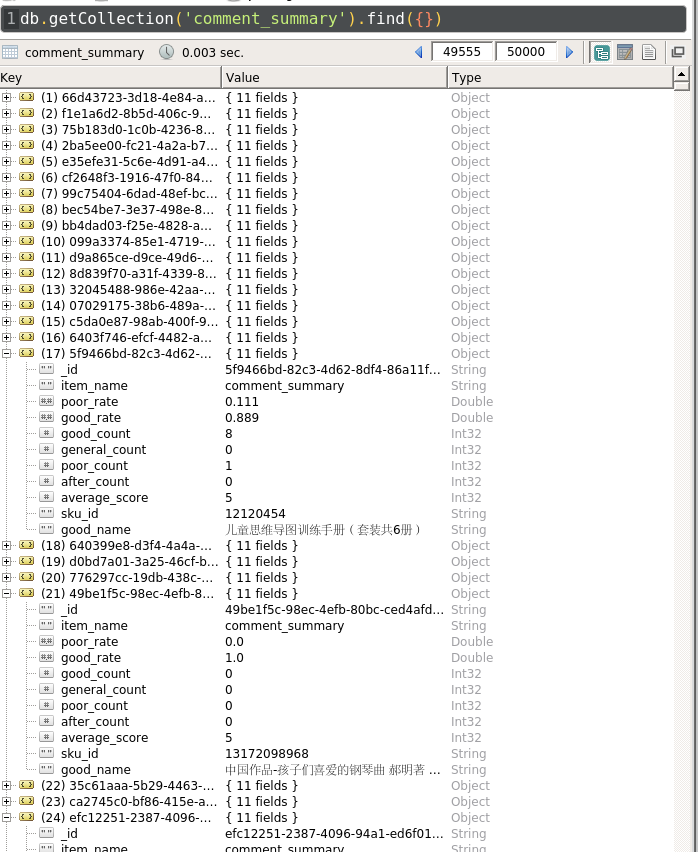{kind=link}
8.3 商品信息
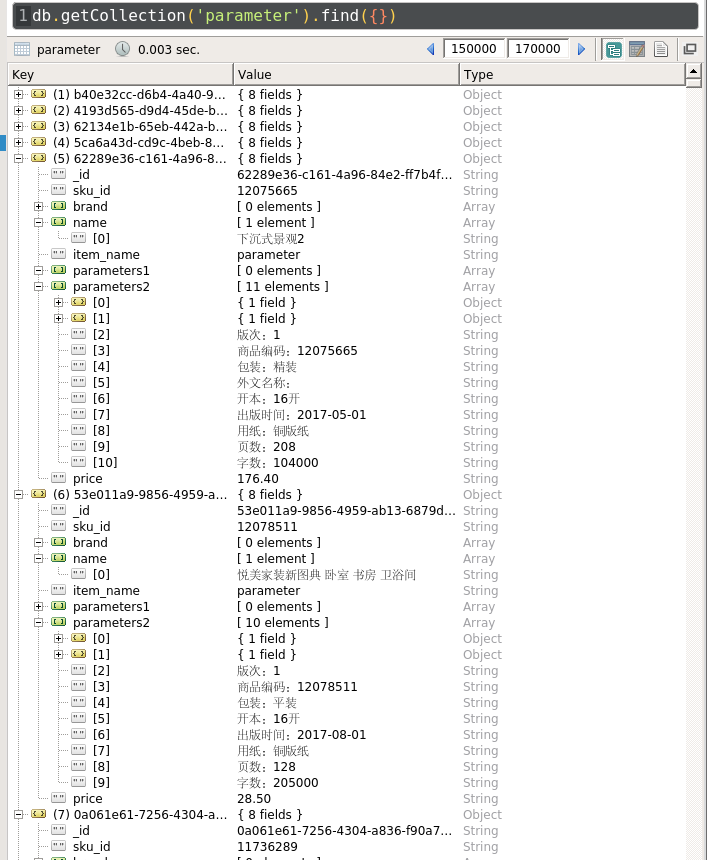{kind=link}
商品信息加上评论数约 150+w.
9 参考及致谢
- https://github.com/noplay/scrapy-graphite
- https://github.com/gnemoug/distribute_crawler
- https://github.com/hopsoft/docker-graphite-statsd
10 项目源码
https://github.com/ramsayleung/jd_spider
 公号同步更新,欢迎关注👻
公号同步更新,欢迎关注👻