1 Distributed Systems for fun and profit
source: http://book.mixu.net/distsys/
2 1. Basic
2.1 Basic concept
本章介绍了分布式系统的基本概念, 例如 scalablity, perfomance, latency, availability
关于 latent, 这里给出了一个很cool的描述:
For example, imagine that you are infected with an airbone virus that turns people into zombies. The laten period is the time between when you became infected, and when you turn into a zombie. That’s latency: the time during which something that has already happed is concealed from view.
关于 availability, 计算公式是:
Availability = uptime / (uptime + downtime)
2.2 Failt tolerance
设计一个可靠的分布式系统, 相当程度上是设计一个fault tolerance 系统, failure 一词 在此章出现了很多次. But without knowing every single aspect of the system, the best we can do is design for fault tolerance.
Fault tolerance: ability of a system to behave in a well-defined manner once faults occur. Fault tolerance boils down to this: define what faults you expect and then design a system or an algorithm that is tolerant of them. You can’t tolerate faults you haven’t considered.
限制分布式系统的主要是两个物理因素:
- 节点数(你想要更多的存储空间, 更强的计算能力, 自然需要更多的节点)
- 节点间的距离(信息传输, 光速是上限)
从设计系统的角度来考虑这两个限制:
- 节点数越多, 出错(failure)的概率就越高(降低可用性, 增加了管理成本)
- 节点数越多, 节点之间的通信就越多(限制节点数与性能之间的线性增长)
- 距离越大, 节点通信的延迟就大(性能下降)
2.3 Abstraction and model
因为真实世界有很多与问题域无关的干扰因素, 为了排队这些干扰, 我们引入了Abstraction和Model的概念.
- Abstraction: it make things more manageable by removing real-world aspects that are not relevant to solving a problem.
- Model: it describes the key properties of a distributed system in a precise manner.
基于不同维度, 可以总结出不同的 Model:
- System model(asynchronous/synchronous)
- Failure model(crash-fail, partitions, Byzantine)
- Consistency model(strong, eventual)
2.4 Partition and replicate
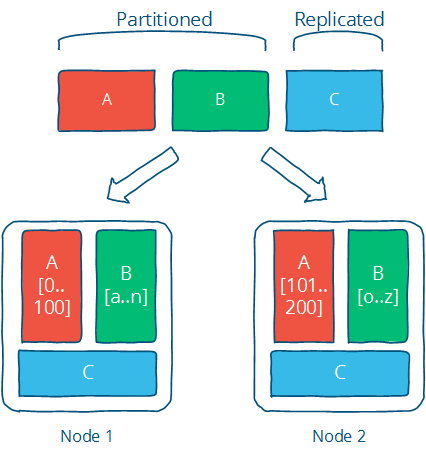
数据在不同节点之间如何存储是个非常关键的问题, 目前有两种经典的数据存储技术, 分片(partitioning)与冗余(replication):
- partitioning: data set can be split over multiple nodes to allow for more parallel processing.
- replication: data set can be copied or cached on different nodes to reduce the distance between the client and the server and for greater fault tolerence.
{kind=link}
partitioning: 相当每个节点存储一部分数据, 所有节点的数据汇总起来就是该系统存储的总数据. 但是某个节点挂了, 该节点的数据就丢了
replication: 不同节点都存储同一份数据, 这样就可以减少读取不同数据的开销, 以及避免某个节点挂了, 导致部分数据不可用的情况. 但是需要更多的存储空间且不同节点之间数据的同步又是个大问题, 可以说是按下葫芦浮起瓢
To replication! The cause of, and the solution to all of life’s problems - Homer J Simpson(我很喜欢这句话)
3 2. Up and down the level of abstraction
3.1 Abstraction
何谓抽象, 有过编程经验的我们自然不会陌生. 抽象, 即去除真实世界与问题域无关的干扰, 专注于问题本身, 使解决方案可被广泛采用.
Abstractions make the world manaeable: simpler problem statements - free of reality - are much more analytically tractable and provided that we did not ignore anything essential, the solutions are widely acclicable.
3.2 A system model
分布式系统的关键属性是分布式, 或者说, 程序运行在分布式环境:
- 并发运行在独立节点
- 通过网络通信, 可能出现某种不确定性或消息丢包
- 没有共享内容或共享锁
上面的特定会带来诸多的影响:
- 每个节点都并发运行程序
- 本地为先: 每个节点都可以快速访问他们的本地状态, 而所有关于全局状态的信息都有可能是过时的
- 节点可能挂掉, 并从故障中恢复回来
- 消息可能延迟或丢失(不同于节点故障, 通常很难区分节点故障或网络故障)
- 节点间的时钟可能不同步(本地时间与全局时间不一定对应, 且很难观察到异常)
通过定义一个模型(model)来标识实现一个分布式系统需要交互的环境与机制:
a set of assumptions about the environment and facilities on which a distributed system is implemented
A robust system model is one that makes the weakest assumptions: any algorithm written for such a system is very tolerant of different environments, since it makes very few and very weak assumptions.
模型需要越少的假设条件, 可以适应的环境就越多. 等价交换, fair enough.
3.2.1 Nodes in our system model
节点是作计算与存储的主机(物理或虚拟主机), 它们有如下属性:
- 可以运行程序
- 可以存储数据到volatile memory(例如内存)或stable state(日志或磁盘)
- 拥有时钟(可以准的或者是不准的)
有很多的故障模型(failure models) 描述了节点挂掉(fail)的方式, 实际中, 大部分的系统都假设是个crash-recovery failure model, 即节点可能挂掉, 但是能从某个状态中恢复回来.
A crash-recovery failure model: that is, nodes can only fail by crashing, and can(possibly) recover after crashing at some later point.
3.2.2 Communication links in our system model
communication links 不知道应该怎么翻译, 通讯链路? 不译也罢
communication links 用于沟通不同的节点, 允许信息在双向流动. 部分算法假设网络是可靠的: 消息永不丢失并且永不延迟. 虽说这样假设有些许道理, 但是通常我们都是假设网络是不可靠, 因此消息可能丢失或者延迟.
节点故障 vs 网络分区故障:
{kind=link}
3.2.3 Timing/ordering assumptions
分布式系统在物理上分布在不同的位置, 这就会无可避免地会带来一个问题, 如果节点之间的距离不同, 那么节点之间的消息将会以不同的时间点, 甚至不同的顺序到达.
有两个主要的时序模型:
- Synchronous system model: Process execute in lock-step; there is a known upper bound on message transimission delay; each process has an accurate clock.(这里的 known upper bound 指的是就是传输层的最大等待时间, 超过即由传输层进行重试. 当然, 这样的假设不大现实, 所以这样的模型实际应用比较少)
- Asynchronous system model: No timing assumptions - e.g. processes execute at indenpendent rates; there is no bound on message transmission delay; useful clocks doesn’t exist.
3.2.4 The consensus problem
共识问题(consensus problem) 是商业分布式系统关注的核心问题之一, 所谓的共识问题, 即若干个计算机或节点就某个值达到共识, 更正式的说法是:
- Agreement: Every corrent process must agree on the same value(不搞多数人的暴政, 只搞全体的暴政)
- Integrity: Every corrent process decides at most one value, and if it decides some value, then it must have been proposed by some process
- Termination: All processess eventually reach a decision.(不达到共识, 今天你就出不了这个门)
- Validity: If all corrent processes propose the same value V, then all correct processes decide V.(咱也不能赖皮)
3.3 The FLP impossibility result
FLP 不可能原理(FLP impossibility result, 以作者的首字母命名, Fischer, Lynch and Patterson): 在网络可靠, 但节点失效(即便只有一个)的最小化异步模型系统中, 不可能存在一个可以解决一致性问题的确定性共性算法.
There does not exist a (deterministic) algorithm for the consensus problem in an asynchronous system subject to failures, even if message can never be lost, at most one process may fail, and it can only fail by carshing(stoppping executing).
FLP impossibility result 告诉我们: 不要浪费时间, 去试图为异步分布式系统设计面向任意场景的共识算法(别忙了, 白费力气的).
FLP impossibility result 定义了一个最坏情况, 在允许节点失效的情况下, 异步系统无法确保共识在有限时间内完成, 包括Paxos, Raft等算法也都存在无法达成共识的极端情况, 只是在工程实践中这种情况出现的概率很小.
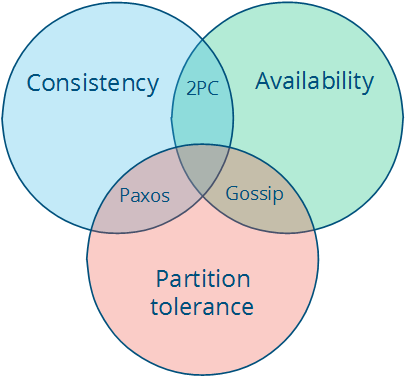
3.4 The CAP theorem
非常有名的CAP 定理, 即无法同时达到C,A,P三个属性, 这三个属性是:
- Consistency: all nodes see the same data at the same time.(准确来说, 应该是Strong Consistency)
- Availability: node failures do not prevent survivors from continuing to operate.
- Partition tolerance: the system continues to operate despite message loss due to network and/or node failure.
最多只能有两个属性被满足, 如下图:
{kind=link}
同时满足三个属性情况是无法实现的, 即中间交集处. 而满足两个属性的系统模型有如下三个:
- CA(consistency + availability): 弱化分区, 保证一致性和可用性, 也变成单机程序, 个人认为Oracle就是其中典范
- CP(consistency + partition tolerance): 弱化可用性, 可能出现无法提供可用结果的情形, 允许少数节点不可用. 典型算法就是Paxos
- AP(availability + partition tolerance): 弱化一致性, 节点之间可能失去联系, 导致全局数据不一致. 典型例子就是诸多的NoSql
CA 和CP 模型都提供强一致的模型, 唯一的差别是, CA系统不允许任何节点故障, 因为CA系统无法区别节点故障和网络故障, 为了避免状态不一致, 只能停写;
而对于 2f+1 个节点的CP系统, 允许 f 个节点故障, 是因为其能通过 single-copy consistency 机制, 能保证状态能达到最终一致, 避免出现状态不一致, 从而支持部分节点不可用
因此, 选择了网络分区, 就需要在高可用和强一致性之间作取舍, 而系统设计即是在基于不同的场景, 作出不同的取舍.
同样, 强一致性和高性能也存在矛盾, 要保证强一致性, 自然需要节点之间通信达到共识, 这自然会拉高延迟, 这也要系统设计者作出取舍.
3.5 Consistency model
何谓一致性模型呢:
Consistency model: a contract between programmer and system, wherein the system guarantees that if the programmer follows some specific rules, the results of operations on the data will be predictable.
一致性模型可以区分成两类: 强和弱一致性模型
- 强一致性模型:
- Linearizable consistency
- Sequential consistency
- 弱(非强)一致性模型
- Client-centric consistency models
- Causal consistenc: strongest model available
- Eventual consistency models
3.5.1 Strong consistency model
Lineariable consistency 和 Sequential consistency 两个模型很相似, 关键的区别是: Lineraiable consistency 要求操作生效的顺序与操作的实际顺序相等; 而Sequential consistency允许对操作进行重新排序, 只要在每个节点上观察到的顺序保持一致.
只要实现了强一致性模型, 模型保证将单机程序扩展到分布式集群时, 程序不会出现任何问题(程序本身的bug就另当别论), 而使用其他非一致性模型的扩展程序时, 就可能会出现问题.
3.5.2 Client-centric consistency model
以客户为中心的一致性(Client-centric consistency model)模型是指以某种方式涉及客户或会话概念的一致性模型.
例如, 以客户为中心的一致性模型可以保证客户永远不会看到一个数据项的旧版本. 这通常是通过在客户端库中建立额外的缓存来实现的.
感觉这种模型见得不是很多.
3.5.3 Eventual consistency
最终一致性(Eventual consistency)模型: 如果你停止更新值, 那么间隔某段时间后, 所有的节点都会看到同样的值. 那么某段时间是多少呢? 如果不能给该值给定个严格下限, 这个模型就和"人最终总会死"模型一样, 用处并不大.
4 3. Time and Order
时序(Time and order)在分布式系统中非常重要, 那么为什么它这么重要呢? 前方提到分布式系统的目标就是可以像在单台机器上解决问题那样, 在多台机器解决同样的问题.
单台机器运行模型是: 单个程序, 单进程, 单内存空间, 运行在单个CPU上, 而操作系统把多个CPU可能运行多个程序,共享内存的情况给抽象掉, 每个操作就好像人们通过一道门一样, 有预先定义好的前者与后者.
现在中, 分布式系统运行在多个节点上, 可能同时拥有多个CPU和待运行操作. 如果还想像单台机器那样, 定义一个全序关系(total order), 要不就需要一个精确的时钟, 每个操作一个时间戳, 通过时间戳推算出执行顺序; 要不就需要额外的通信, 指定对应的序号.
但维护精确的时钟困难且不可靠, 额外的通信成本高.
4.1 Total and partial order
全序关系(total order)和偏序关系(partial order), 两个数学概念, 作者的解释有点简略, 当初上数学课又没有好好听课, 所以相关的概念不是很理解, 知乎上面有个挺详尽的解释:
假设A是一个集合 {1,2,3} ;R是集合A上的关系,例如{<1,1>,<2,2>,<3,3>,<1,2>,<1,3>,<2,3>}
自反性:任取一个A中的元素x,如果都有<x,x>在R中,那么R是自反的.
对称性:任取一个A中的元素x,y,如果<x,y> 在关系R上,那么<y,x> 也在关系R上,那么R是对称的.
反对称性:任取一个A中的元素x,y(x!=y),如果<x,y> 在关系R上,那么<y,x> 不在关系R上,那么R是反对称的.
传递性:任取一个A中的元素x,y,z,如果<x,y>,<y,z> 在关系R上,那么 <x,z> 也在关系R上,那么R是对称的.
偏序: 设R是非空集合A上的关系,如果R是自反的,反对称的,和传递的,则称R是A上的偏序关系.
全序:如果R是A上的偏序关系,那么对于任意的A集合上的 x,y,都有 x <= y,或者 y <= x,二者必居其一,那么则称R是A上的全序关系.
所以可以看到,全序也是一种偏序. 偏序究竟在说啥,关键在于反对称性上,就是说,<x,y> 在关系R上,那么 <y,x> 不在关系R上,那我问你,<y,x> 关系是啥,就是大家都不知道.
所以说偏序就在于你的集合A={1,2,3,4},有一些元素的关系根据R你是得不出的. 那么既然你不知道这个<y,x>,那么全序关系上,就多加一个条件,都有 x <= y,或者 y <= x,二者必居其一,这样你总知道了吧.
偏序举例:假设有 A={1,2,3,4},假设R是集合A上的关系:{<1,1>,<2,2>,<3,3>,<4,4>,<1,2>,<1,4>,<2,4>,<3,4>},
那么:
- 自反性:可以看到 <1,1>,<2,2>,<3,3>,<4,4> 都在R中,满足.
- 反对称性:由于 <1,1>,<2,2>,<3,3>,<4,4> 不属于 x !=y ,所以不考虑这4种,对于 <1,2>,有 <2,1> 不在R中;对于<2,4> 有<4,2>不在R中;对于<3,4> 有<4,3> 不在 R中,满足.
- 传递性:<1,1><1,2>在R中,并且<1,2>在R中;<1,1><1,4>在R中,并且<1,4>在R中;<2,2><2,4>在R中,并且<2,4>在R中;<3,3><3,4>在R中,并且<3,4>在R中;等等其他,满足.
所以说R是偏序关系.
全序举例:
假设有 A={a,b,c},假设R是集合A上的关系:{<a,a>,<b,b>,<c,c>,<a,b>,<a,c>,<b,c>}和上述一样,可以证明具有自反性,反对称性,传递性,所以是偏序的.
又因为有 <a,b>,<a,c>,<b,c>, 也就是说两两关系都有了,所以满足对于任意的A集合上的 x,y,都有 x <= y,或者 y <= x,二者必居其一,所以说是全序关系.
目前还不是很清楚有什么用处.
4.2 What’s time
Time is a source of order. 时间可以解析成以下三种形式:
- Order: 当提到时间是序列的来源时, 我们是在说:
- 我们可以给无序事件指派时间戳, 以此排序
- 我们可以使用时间戳来指定操作或者消息分发的顺序
- 我们可以通过时间来判断某个时间是否在另外一个事件前发生.
- Interpretation: 时间戳所代表的时间可以解析成秒, 分, 时, 日等人类可读的标识.
- Duration: 代表真实世界流逝的时间. 计算机世界的算法通常不关系时间的绝对值或人类可读的标识, 但duration 可被用于作某些重要的判断, 例如某个节点是延迟高还是挂了.
4.3 Does time process at the same rate everywhere
在任何地方, 时间流逝的速度是一样的么? 对于这个问题, 有三个不同的答案(即使是在物理世界, 答案也是, 不一样. 相对论说的):
- “Global clock”: yes
- “Local clock”: no, but
- “No clock”: no
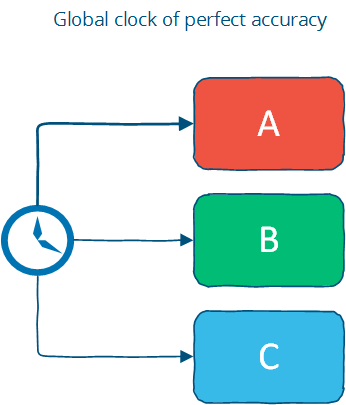
4.3.1 Time with a “Global-clock” assumption
全局时钟(Global clock)模型假设有一个完美的全局时钟, 并且所有节点都与这个时钟通信, 且每个节点都精确同步, 且没有时间漂移:
{kind=link}
但是实际不存在这样的时钟, 任何的时钟都会有一定的精度损失, 并且时钟很难避免出现问题: 有人误修改了时钟; 或者有台过时的机器加入集群, 或者时钟因硬件故障而出现漂移.
不过, 工程实践中的确有程序使用这样的模型:
- Facebook的Cassandra: 假设时钟是同步的, 因为它使用时间戳来处理写冲突, 以最新的时间为准
- Google的Spanner: 使用=TrueTime= API, 保证时间同步的条件下, 又消除了时间漂移的最坏情况.
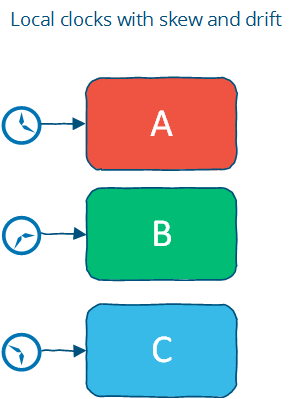
4.3.2 Time with a “Local-clock” assumption
每台机器有自己的时钟, 但是没有全局时钟, 这意味着你不能使用时间戳来比较两台不同机器操作的顺序.
{kind=link}
此模型更接近于真实世界, 它指定一个偏序关系: 节点内是有序的, 但是无法仅通过时间戳来进行跨节点排序.
4.3.3 Time with a “No-clock” assumption
顾名思义, 无时钟模型不使用时间来排序, 而是使用另外的方式, 例如逻辑时间.
这个模型也是偏序的: 事件在某个节点, 可以只通过计数器来进行排序, 但是跨系统排序需要额外的信息交换
当时钟不再使用, 跨节点排序的最大精度上限就由通信延迟决定了. 逻辑时间, 最有名的就是Lamport clock, Lamport就是Paxos之父.
4.4 Vector clocks(time of causal order)
物理时钟通过计数数和通信来跨分布式系统决定事件顺序, 而 Lamport clock 和 Vector clock是物理时钟的代替品. 使用Lamport clock的时候, 每个进程通过以下规则来维护一个计数器:
- 每当一个进程起作用(does work)时, 递增计时器
- 每当一个进程发送一条消息时, 附带上此计时器
- 当收到一条消息的时候, 更新计时器的值为
max(local_counter, received_counter) + 1
Lamport clock是偏序关系, 当 timestamp(a) < timestamp(b), 意味着:
a可能比b先发生a可能无法与b进行比较
已知的时钟一致性条件: 如果一个事件A比事件B先发生, 那么事件A的逻辑时钟也会先于事件B. 如果 a 和 b 来自相同的因果史, 即两个时间戳值都是由同一个进程产生; 或者 b 是 a 发送的消息的响应, 那么 a 先于 b 发生.
由此可见, 如果两个系统没有交集, 那么它们的时钟值将无法比较. 不过, 这里还有个关键的属性, 某个节点而言, 如果它以 ts(a) 来发送消息, 并以 ts(b) 收取此条消息的响应, 那么 ts(b) > ts(a)
Vector clock是Lamport clock 的扩展, 对于有 N 个节点的分布式系统, 会维护一个size = N的数组 [t1, t2, ....], 对应记录每个节点的计数. 计数值的更新规则:
- 每当一个进程起作用(does work)时, 递增数组对应该进程的计数值
- 每当一个进程发送一条消息, 附带上整个计数器数组
- 每当收到一条消息:
- 更新数组中的每个元素
max(local, received) - 递增数组中当前节点对应的计数值
- 更新数组中的每个元素
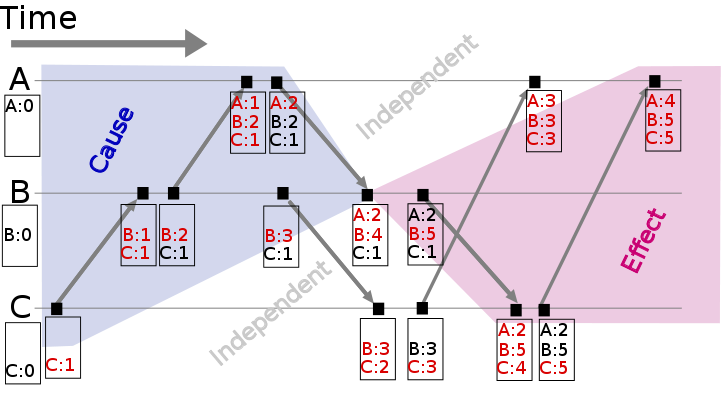{kind=link}
4.5 Failure detector(time for cutoff)
假设程序运行在某个节点A上, 它与节点B通信异常了, 怎么判断是网络延迟还是节点B挂了呢? 如果过了相当一段时间后, 我们可以判断节点B挂了, 那么相当一段时间又是多长呢?
Chandra 提出了failure detector这个概念来解决这个问题, failure detector包括两个属性, 完整性(completeness)与精确性(acuracy).
- Strong completeness: Every crashed process is eventually suspected by every correct process
- Weak completeness: Every crashed process is eventually suspected by some correct process
- Strong accuracy: No correct process is suspected ever
- Weak accuracy: Some correct process is never suspected.
完整性比准确性更容易实现, 避免错付没有问题的进程是很难的, 除非可以假设消息延迟的上限, 但是这样的假设只能在同步模型中实现, 所以failure detector在同步模型中可以达到相当的高精度. 而对于没有延迟上限的系统(异步模型), failure detector能做到的极限就是最终准确.
下面的图阐述了系统模型与问题可解决性之间的关系:
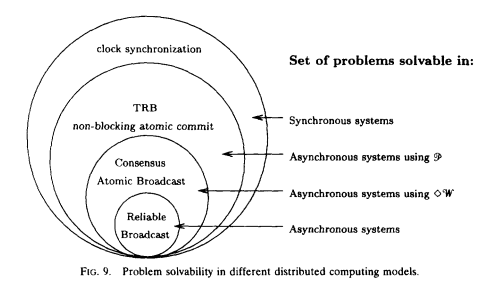{kind=link}
理想情况下, 我们希望failure detector可以根据网络条件动态调整检测阈值, 以此避免硬编码阈值, 例如TCP的动态超时计算算法那样. Cassandra 使用的是 accrual failure detector, 输出结果是一个故障的可疑度(0到1之间值), 而不是简单的 挂/没挂, 以此为应用根据可疑度自行决断, 提供更高的灵活度.
4.6 Time, order and performance
使用全序关系也是可能的, 但是为了协调全局顺序, 会付出高昂的性能代价.
如果你对时间/顺序/同步性要求没有那么高, 你可以获得相当的性能提升. 那么, 什么时候需要顺序来保证正确性呢? 后面提到 CALM定理 会为你提供答案.
说到底, 又是取舍的话题, 下面的情景只存在电影中:
{kind=link}
5 4. Replication: Preventing Divergence
复制(replication)是分布式系统需要考虑的诸多问题中的其中一项, 但是却非常关键, 并与选主(leader election), 失败检测(failure detection), 共识(consensus)和原子广播(atomic broadcast)等问题息息相关.
现在让我们先来看复制长什么样, 假设有某个数据库, 存储初始状态的数据, 客户端请求修改数据状态:
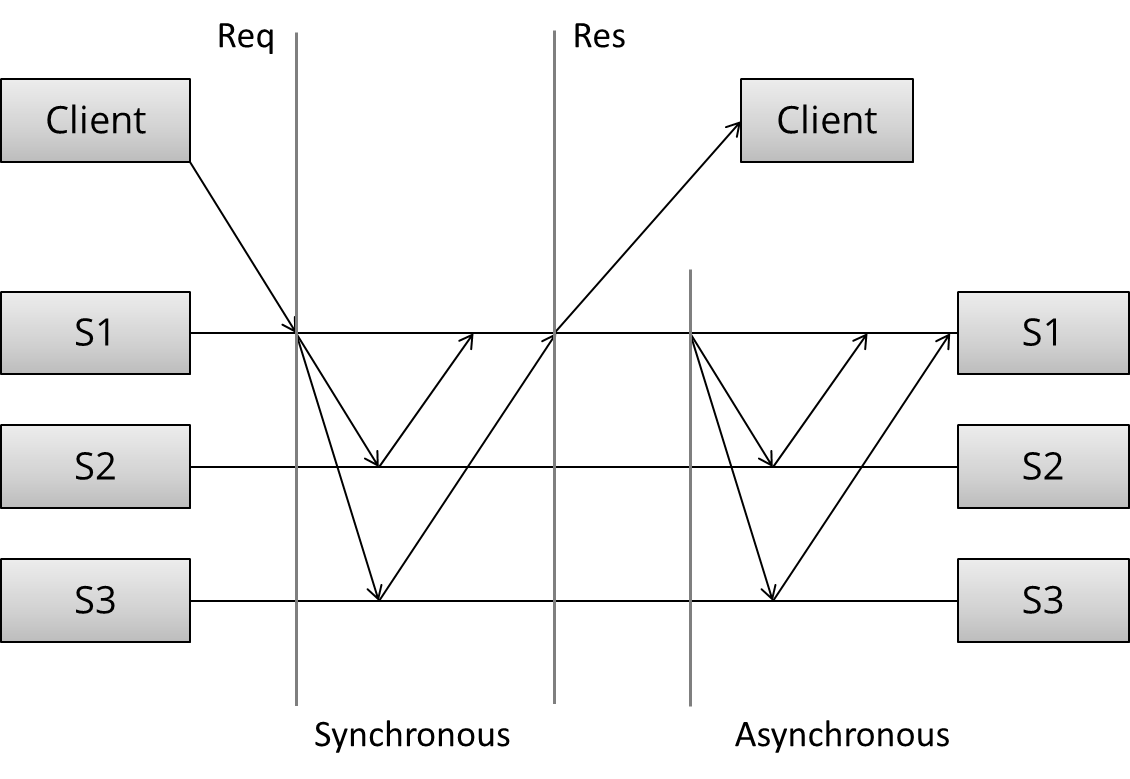{kind=link}
复制的模式可以划分成以下几个步骤:
- (Request) 客户端发送请求到服务端
- (Sync) 同步流程开始处理
- (Response) 响应返回到客户端
- (Async) 异步流程开始处理
由此可见, 复制模式可以划分为同步复制(Synchronous replication)与异步复制(Asynchronous replicatin)
5.1 Synchronous replication
同步复制模式(也被称为active/eager/push/pessimistic replication):
{kind=link}
我们可以看到三个不同的阶段:
- 首先,客户端发送请求.
- 接下来,处理此前提到的同步复制流程, 即客户端被阻塞至服务端响应. S1与S2, S3通信, 并等待, 直到收到所有服务器的响应
- 向客户端发送响应, 告知其结果(成功或失败)
可以观察到, 这是一种 N 对 N 的模式: 在返回响应前, 该请求必须被每个节点所确认, 任何一个节点都不允许丢数据, 否则系统就无法成功向所有节点写入数据, 就无法继续提供写入服务, 可能只允许提供只读服务. 此外, 该系统的响应速度取决于最慢那台服务器的响应速度.
虽说同步模式性能有所欠缺, 但是能提供强持久性保证(strong durability guarantees): 只要向客户端返回成功, 就能保证所有节点写入成功, 要丢失这次的更新数据, 就需要所有节点都丢失.
5.2 Asynchronous replication
异步模式(也被称为 passive/pull/lazy replication):
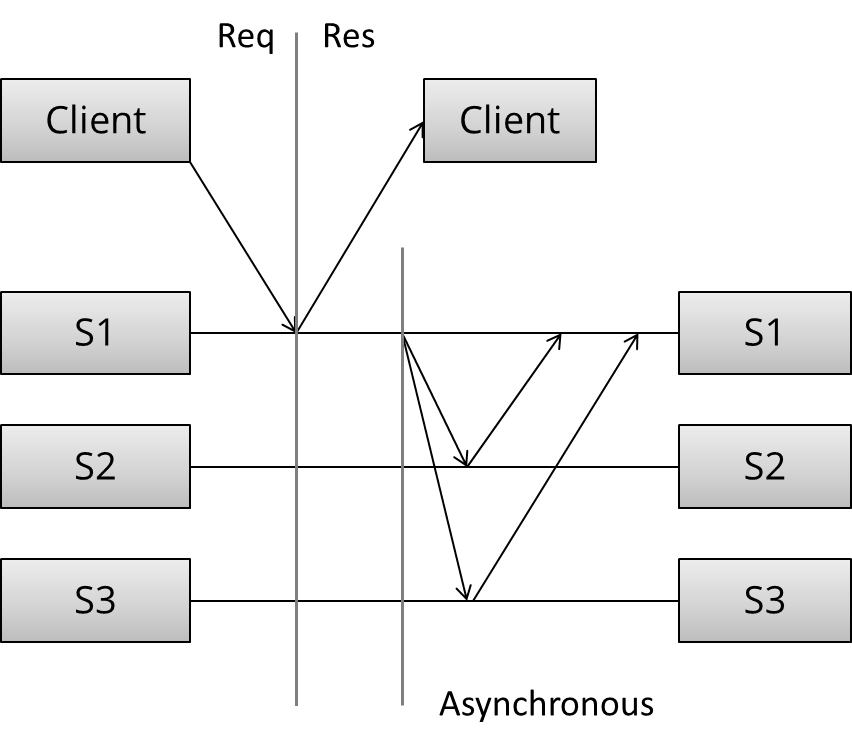 在收到客户端的请求后, Master 节点(S1)立即返回了一个响应, 然后在若干时间后, 执行异步复制: Master 节点以某种模式与其他节点通信, 通知他们更新数据副本. 细节就取决具体的算法.
在收到客户端的请求后, Master 节点(S1)立即返回了一个响应, 然后在若干时间后, 执行异步复制: Master 节点以某种模式与其他节点通信, 通知他们更新数据副本. 细节就取决具体的算法.
这是一个 1 对 N 的模型, 立即返回一个响应, 然后在稍后的某个时间进行复制. 从性能的角度解析, 异步模式可以快速响应, 客户端无需阻塞等待.
但只能提供弱持久性保证(weak durability guarantees), 只有一个节点持有更新数据, 如果这个节点挂了, 又还没有复制到其他节点, 数据就永久丢失了, 所以给客户端响应成功, 也只能表示, 有概率复制成功.
5.3 An overview of major replication approaches
在讨论了两种基本的复制模式:同步复制和异步复制之后,我们来看看主要的复制算法.
有很多对复制算法进行分类的指标, 作者认为第二个指标是(继同步与异步之后):
- 避免数据不一致的复制算法
- 承受数据不一致风险的复制算法
第一类算法的特征是它们"看起来像个单机系统", 尤其是出现故障的时候, 算法确保系统中只有一个复本是可用的(active), 此外, 该系统保证副本数据总是一致的(consensus problem).
不同复制算法需要交换的消息数:
- 1 * n 条消息(asynchronoous primary/backup)
- 2 * n 条消息(synchronous primary/backup)
- 4 * n 条消息(2-phase commit, Multi-Paxos)
- 8 * n 条消息(3-phase commit, Paxos with repeated leader election)
不同的复制算法有不同的特点, 以下是改编自Google 的Ryan Barret 的一张图:
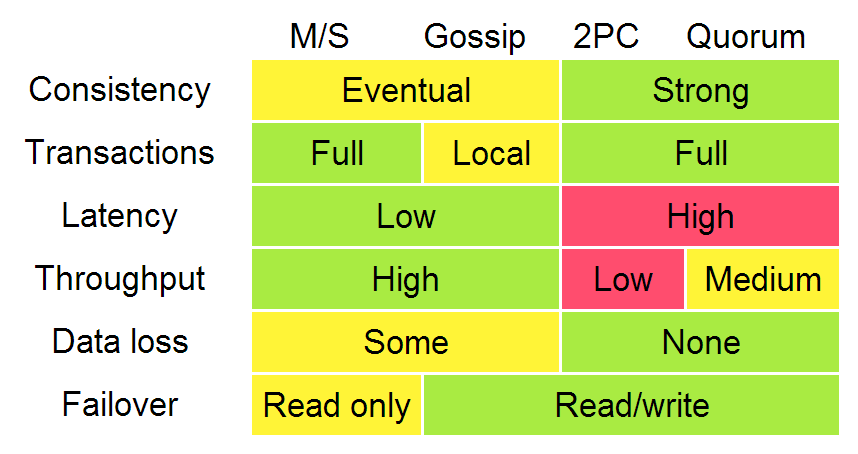{kind=link}
上图中的一致性、延迟、吞吐量、数据丢失和故障转移的特点,实际上可以追溯到两种不同的复制模式:
同步复制(在响应前等待)和异步复制(立即响应).
当你等待时,你会得到更差的性能,但有更强的保证.
5.4 Primary/backup replication
主从复制, 可能是最常用的复制算法, 也是最基本的复制算法. 所有更新操作都是在主机进行, 然后复制数据到备机. 有两种变体:
- synchronous primary/backup replication
- asynchronous primary/backup replication
前者需要两条消息(update + ack), 而后者只需要一条消息(update). 主/从复制非常常见, MySQL 复制使用的就是主/从复制, MySQL 支持三种模式复制:
- 同步: 客户端请求, 先写入主机, 然后同步到所有备机, 成功后响应客户端, 在此之间, 阻塞客户端(性能最差)
- 异步: 客户端请求, 先写入主机, 然后响应客户端, 再同步备机(同步备机前主机挂, 则丢失数据)
- 半同步: 客户端请求, 先写入主机, 再同步到备机, 响应客户端, 然后再同步到其他备机(可靠性与性能的折衷)
但是即使是半同步模式, 也会存在问题:
- 主机收到一个更新请求,并将其同机给备机
- 备机同步成功并ACK主机
- 主机在向客户端响应请挂了
客户端认为是提交失败, 但实际备机写入成功; 如果备机升主, 数据就会有问题.
所以可见, 主/从复制模式提供的一致性保证, 只能说明是"尽力而为". 为了避免异常导致一致性保证被违反, 我们需要增加多一轮的消息传递, 就来到了段提供协议(2PC)
5.5 Two phase commit (2PC)
下图说明两阶段提交(2PC)的消息流:
| |
2PC流程如下:
- 在一阶段(投票), 协调者将更新请求发送给所有的参与者, 每个参与者处理请求并决定是commit 还是 rollback.
- 在二阶段(决定), 协调者决定结果并通知每个参与者.
2PC容易出现阻塞,因为单个节点的故障(参与者或协调者)会阻塞进度,直到该节点恢复; 并且因为它是 N 对 N, 所以在最慢的节点确认前不能写入. 因此2PC的性能不理想也是情理之中.
回想之前的CAP理论, 2PC就属于是CA, 它弱化了分区容忍性,所以2PC解决的故障模型不包括网络分区, 当出现网络分区的时候, 2PC就懵了, 不知所措, 只能等待网络分区合并.
2PC在性能和容错性之间取得了很好的平衡,这就是为什么它在关系型数据库中一直很受欢迎.
然而,较新的系统通常使用分区容忍的共识算法(partition tolerant consensus algorithms),因为这样的算法可以提供从临时网络分区中的自动恢复,以及更优雅地处理节点间延迟的增加.
5.6 Partition tolerant consensus algorithms
提起分区容忍的共识算法, 最有名的就是Paxos算法, 但是Lamport大神把他的论文写小说, 让大家苦不堪言, 正因为Paxos出了名的难理解, 所以出现了Raft. 但Goole Chubby的作者Mike Burrow认为:
There is only one consensus protocol, and that’s Paxos – all other approaches are just broken versions of Paxos. (世界上只有一种共识协议,就是Paxos,其他所有共识算法都是Paxos 的残缺版本)
首先让我们看下分区容忍算法的特点:
5.6.1 Network partition
网络分区是指一个或几个节点的网络链接失效. 节点本身继续保持活跃,它们甚至可以接收来自网络分区一侧的客户端的请求.
网络分区很棘手的,因为在网络分区期间,不可能区分一个节点是挂了呢还是出现网络分区导致请求不可达. 如果发生了网络分区,但没有节点发生故障,那么系统就被分成两个分区. 如下图:
2个节点时, 节点故障vs 网络分区:
{kind=link}
3个节点时, 节点故障vs 网络分区:
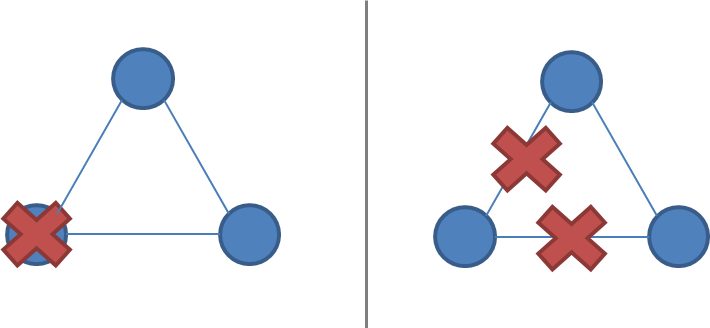{kind=link}
分裂成两个网络分区时, 共识算法必须要处理这种对称情况, 只允许一个网络分区保持活跃.
5.6.2 Majority decisions
出现网络分区时, 是怎么保证只有一个分区是活跃的呢? 答案就来自于日常生活: 投票. 只要只要 N 个节点中的 (N/2+1) 投票同意更新, 系统就更新成功, 可以继续运行, 少数派就可以自己独处, 直到分区合并.
因此, 使用共识算法的系统的节点数都是奇数(3,5或7), 避免出现无法投票成功的情况. 例如,如果节点数为3,那么系统可以容忍一个节点故障;有5个节点,系统容忍两个节点故障.
除去网络分区, 基于多数人投票的共识算法还可以容忍抖动或故障导致的反对票, 并以此提供系统健壮性.
5.6.3 Roles
构建一个系统有两种途径:所有节点可以有相同的责任,或者节点可以有单独的、不同的角色.
而共识算法通常选择为每个节点设置不同的角色, Paxos中的提议者与投票者, 对应Raft中的领导与从众, 也就是领袖与民众. 拥有领袖是一种优势, 可以让系统更有效率.
角色在系统正常运行过程是固定的, 但这并不意味着领导不会出现意外, 或者可以无限期当领导.
5.6.4 Epochs
在Paxos和Raft算法, 正常运行的每个一个时间被称为一个纪元(有魔戒的味道了. 在Raft中被称为期限), 在每个纪元期间,只有一个节点是指定的领导者.
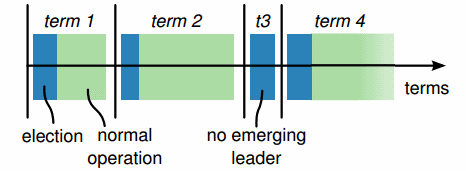{kind=link}
选举成功后,同一个领导者会协调到纪元结束(任期到了就要换人, 不能賴着不走.). 如上图所示(来自Raft的论文),一些选举可能会失败,导致纪元立即结束.
5.6.5 Leader changes
所有节点开始时都是民众;一个节点在开始时被选为领袖. 在正常运行期间,领袖与民众通过心跳包保持通信,民众可以检测领导是否挂了或被分割到另一个网络分区.
当一个节点检测到领导变得没有反应时(或者在最初的情况下,不存在领导者),它就会切换到一个中间状态(在Raft中称为 “候选”),在那里它将术语/周期值增加1,启动竞选程序并竞争成为新领导(王侯将相, 宁有种乎).
为了当选为领导,一个节点必须获得多数票. 分配选票的一种方法是以先来先得的方式分配选票;这样一来,最终会选出一个领导者.
5.6.6 Normal operation
在正常操作中,所有的提议都要经过领导节点.
当客户端提交一个提案(如更新操作), 领导会联络所有节点. 如果不存在竞争性的提议, 领导者就会提出该值. 如果大多数民众接受该值, 那么该值就被认为被接受了. 一旦一个提案被接受, 其值就不能改变, 关于此, Lamport的表述是:
P2: If a proposal with value v is chosen, then every higher-numbered proposal that is chosen has value v.
为了实现这个属性, 领导提案前必须先询问民众, 编号最高的提案与值是哪个, 如果领导发现现在已经有一个提案在执行, 那么就必须先把这个提案执行完, 而不是提出自己的提案.
即:
P2c. For any v and n, if a proposal with value v and number n is issued [by a leader], then there is a set S consisting of a majority of acceptors [followers] such that either (a) no acceptor in S has accepted any proposal numbered less than n, or (b) v is the value of the highest-numbered proposal among all proposals numbered less than n accepted by the followers in S.
这是Paxos算法的核心, 为了确保领导在咨询民众编号最高的提案与值时, 没有竞争提案出现,领导要求民众不能接受比当前编号低的提案. 所以把Lamport的话组合起来, 使用Paxos算法要达到一个共识, 需要两轮的沟通:
| |
第一轮, 带上最近的提案与值, 就是为了避免在第一轮问询与第二轮更新之间, 接受一个新更新请求, 就工程实践的角度来看, 此处的previous value with the highest proposal number 相当于是一个乐观锁, 避免被更少的值所更新; 假如中间插入的更新请求成功, highest proposal number 就不是第一轮问询持有的值, 更新就会失败, 避免被覆写.
5.7 Paxos, Raft, ZAB
有名的分区容忍性共识(Partition tolerant consensus algorithms)算法:
- Paxos: 以希腊的Paxos岛命名, 最重要的分区容忍性共识算法之一(甚至可以把之一去掉), 以难实现难理解著称(但Lamport说Paxos 很简单, 受不了一群人整天问他Paxos算法, 就写了篇 Paxos Make Simple的论文, 人与神的差距), 被用在谷歌的许多系统中, 例如Chubby, BigTable, Spanner等等
- ZAB: the Zookeeper Atomic Broadcast protocol, 被用在Apache Zookeeper中, Zookeeper 可以算是Chubby的开源版本
- Raft: 对Paxos算法的简化和改进, 被认为更易于学习与理解.
5.8 Replication methods with strong consistency
以下是支持强一致性复制算法的一些特征:
- Primary/Backup
- 单一, 静态 Master 节点(主机)
- Slave 节点(备机)不参与执行操作
- 复制延迟无上限
- 不支持分区
- 手动/临时故障切换,不容错,“热备份”
- 2PC
- 一致表决: commit or rollback(to be or not to be)
- 静态 Master 节点
- 不支持分区, 对尾部延迟(tail latency)敏感
- Paxos
- 多数人投票
- 动态 Master 节点
- 可应对N/2 - 1个节点的故障
- 对尾部延迟(tail latency)不敏感
6 5. Replication: Accepting Diveragence
笔记待续
 公号同步更新,欢迎关注👻
公号同步更新,欢迎关注👻