1 Preface
I have been maintained a legacy distributed timer for months for my employer, then some important pay business are leveraging on it, with 1 billion tasks handled every day and 20k tasks added per second at most.
Even though it’s old and full of black magic code, but it also also have insighted and well-designed code. Based on this old, running timer, I summarize and extract as this article, and it wont include any running code(perhaps pseudocode, and a lot of figures, as an adage says: A picture is worth a thousand words).
if you are curious about the reason(I personally suggest to watch the TV series Silicon Valley, Richard has gave us a good example and answer)
2 Design
2.1 Algorithm
There are several algorithms in the world to implement timer, such as Red-Black Tree, Min-Heap and timer wheel. The most efficient and used algorithm is timer wheel algorithm, and it’s the algorithm we focus on.
As for timing wheel based timer, it can be modelled as two internal operations: per-tick bookkeeping and expiry processing.
- Per-tick bookkeeping: happens on every ’tick’ of the timer clock. If the unit of granularity for setting timers is T units of time (e.g. 1 second), then per-tick bookkeeping will happen every T units of time. It checks whether any outstanding timers have expired, and if so it removes them and invokes expiry processing.
- Expiry processing: is responsible for invoked the user-supplied callback (or other user requested action, depending on your model).
2.1.1 Simple Timing Wheels
The simple timing wheel keeps a large timing wheel, the below timing wheel has 8 slots, and each slot is holding the task which is going to be expired. Supposing every slot presentes one second(one tick as a second), then the current slot is slot 1, if we want to add a task needed to be triggered 2s later, then this task will be inserted into slot 3.
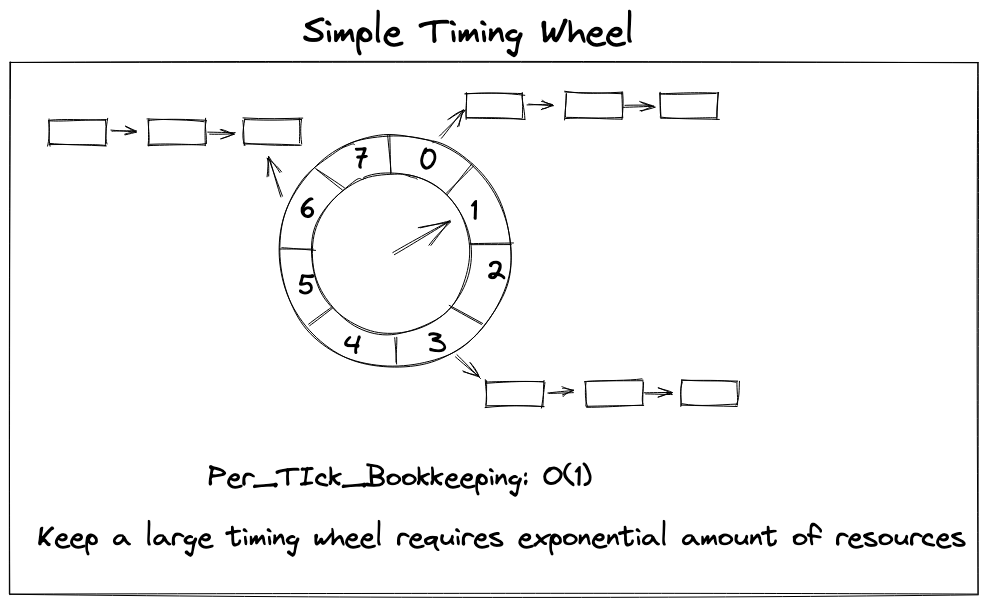
- per-tick bookkeeping: O(1)
What happen if we want to add a task needed to be launched 20s later, the answer is we have no way to do so since there are only 8 slots. So if we have a large period of timer task, we have to maintain a large timing wheel with tons of slots, which requires exponential amount of memory.
2.1.2 Hashed Timing Wheel
Hashed Timing Wheel is an improved simple timing wheel. As we mentioned before, it will consume large resources if timer period is comparatively large. Instead of using one slot per time unit, we could use a form of hashing instead. Construct a circular buffer with a fixed number of slots(such as 8 slots). If current slot is 0, we want store 3s later task, we could insert into slot 3, then if we want bookkeep 9s-later task, we could insert into slot 1(9 % 8 = 1)
- per-tick bookkeeping: O(1) - O(N)
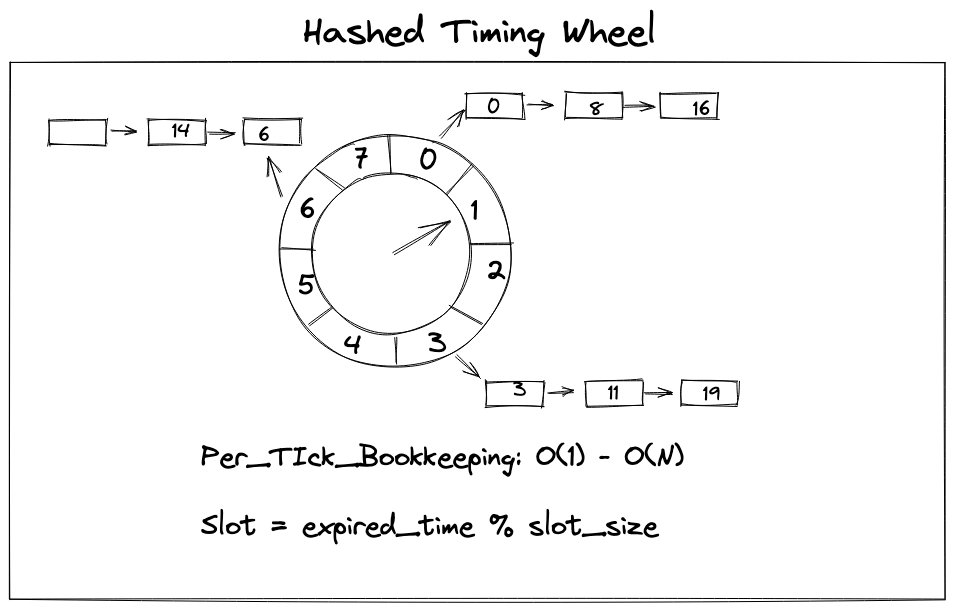
It’s a tradeoff strategy, We trade space with time.
2.1.3 Hierarchical Timing Wheels
Since simple timing wheels and hashed timing wheel come with drawback of time efficiency or space efficiency. Back to 1987, after studying a number of different approaches for the efficient management of timers, Varghese and Lauck posted a paper to introduce Hierarchical Timing Wheels
Just make a long story short, I won’t dive deep into hierarchical timing wheels, you could easily understand it by a real life reference: the old water meter

the firse level wheel(seconds wheel) rotates one loop, triggering the second level(minutes wheel) ticks one slot, same for the third level(hour wheel). Therefore, we present a day(60*60*24 seconds) with 60+60+24 slots. If we want to present a month, we only need to a four level wheel(month wheel) with 30 slots.
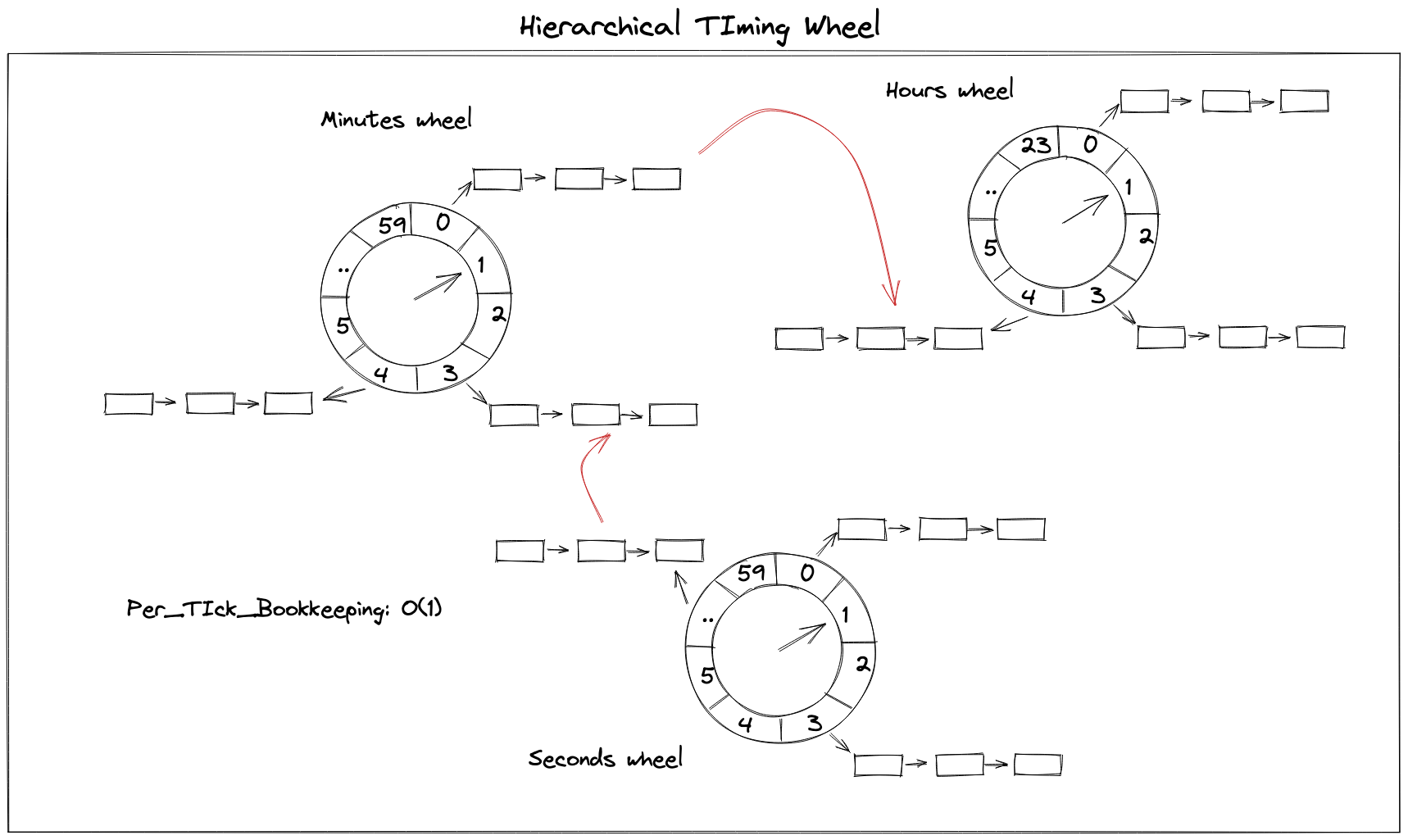
- per-tick bookkeeping: O(1)
2.2 Per-tick bookkeeping
After introducing timing wheel algorithm, let’s go back to the topic about designing a reliable distributed timer, it’s essential to decide how to store timer task. Taking implementation complexity and time, space trade off, we choose the Hashed Timing Wheel algorithm.
There are several internal components developed by my employer, one of them is named TableKV, a high-availability(99.999% ~ 99.9999%) NoSql service. TableKV supports 10m buckets(the terminology is table) at most, every table comes with full ACID properties of transactions support. You could simply replace TableKV with Redis as it provides the similar bucket functionality.
2.2.1 Insert task into slot
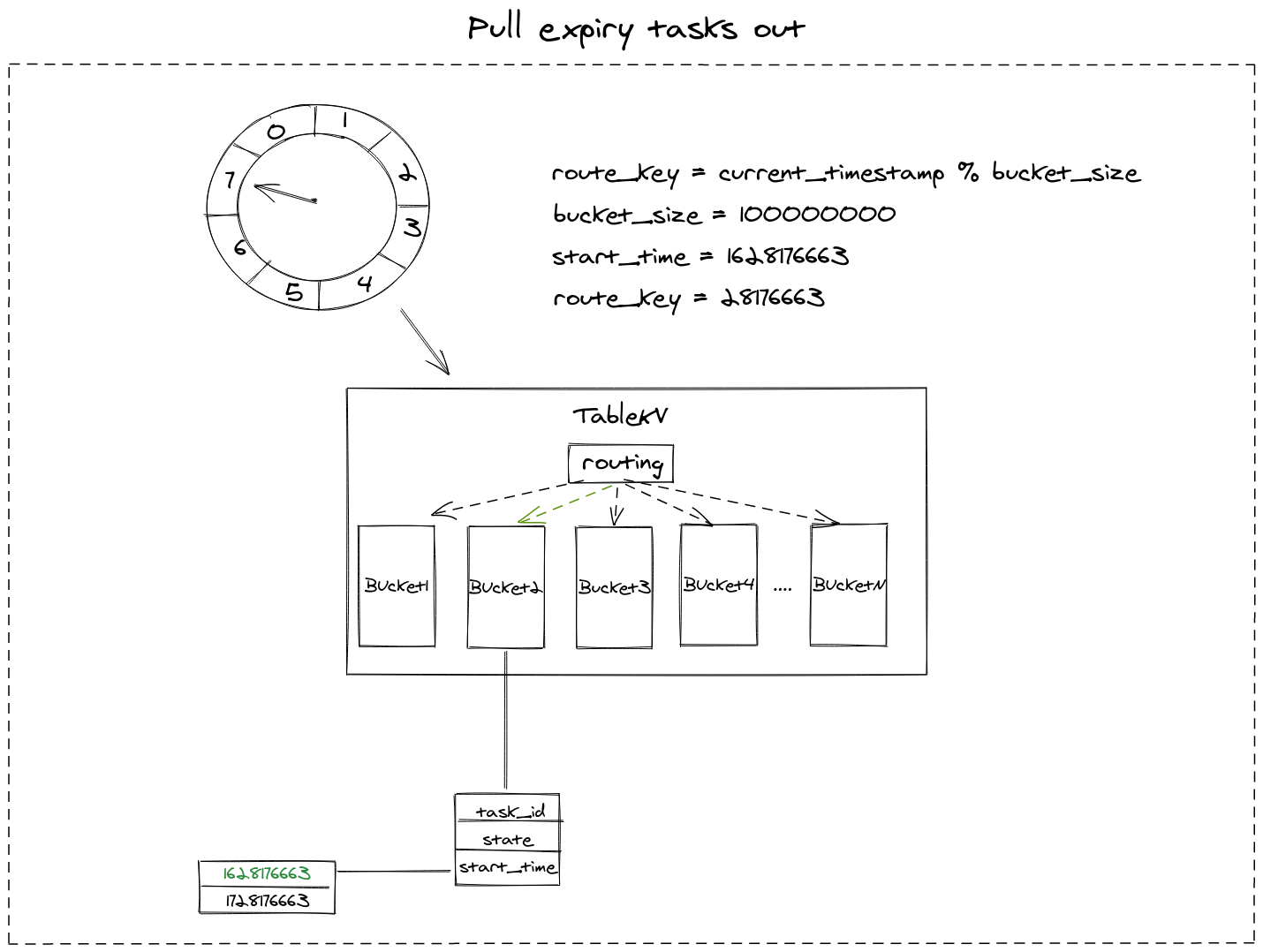
We are going to implement Hashed Timing Wheel algorithm with TableKV, supposing there are 10m buckets, and current time is 2021:08:05 11:17:33 +08=(the UNIX timestamp is =1628176653), there is a timer task which is going to be triggered 10s later with start_time = 1628176653 + 10 (or 100000010s later, start_time = 1628176653 + 10 + 100000000), these tasks both will be stored into bucket start_time % 100000000 = 28176663
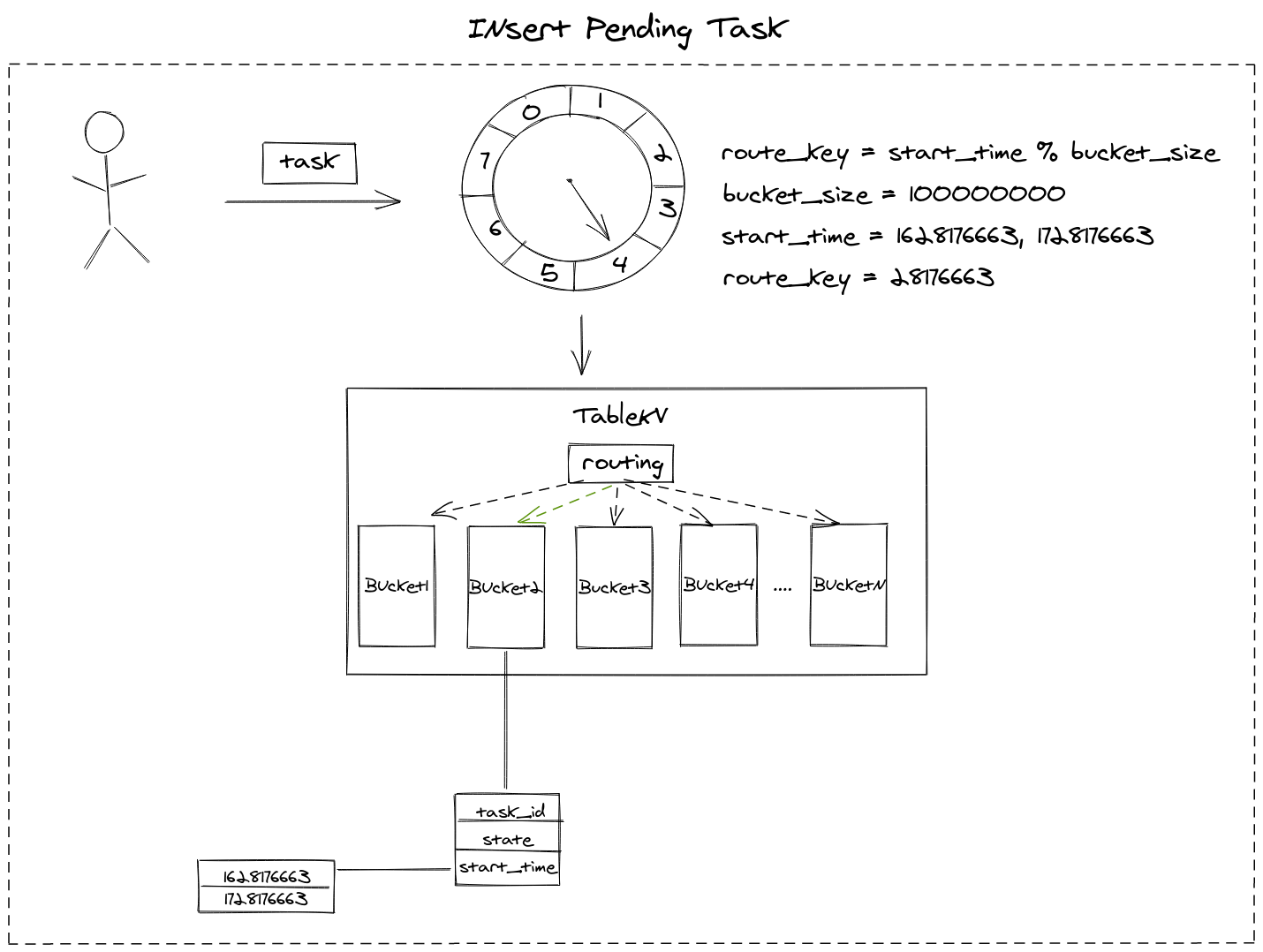
2.2.2 Pull task out from slot
As clock tick-tacking to 2021:08:05 11:17:43 +08(1628176663), we need to pull tasks out from slot by calculating the bucket number: current_timestamp(1628176663) % 100000000 = 28176663. After locating the bucket number, we find all tasks in bucket 28176663 with start_time < current_timestamp=, then we get all expected expiry tasks.
2.3 Global clock and lock
As we mentioned before, when the clock tick-tacks to current_time, we fetch all expiry tasks. When our service is running on a distributed system, it’s universal that we will have multiple hosts(physical machines or dockers), with multiple current_times on its machine. There is no guarantee that all clocks of multiple hosts synchronized by the same Network Time Server, then all clocks might be subtly different. Which current_time is correct?
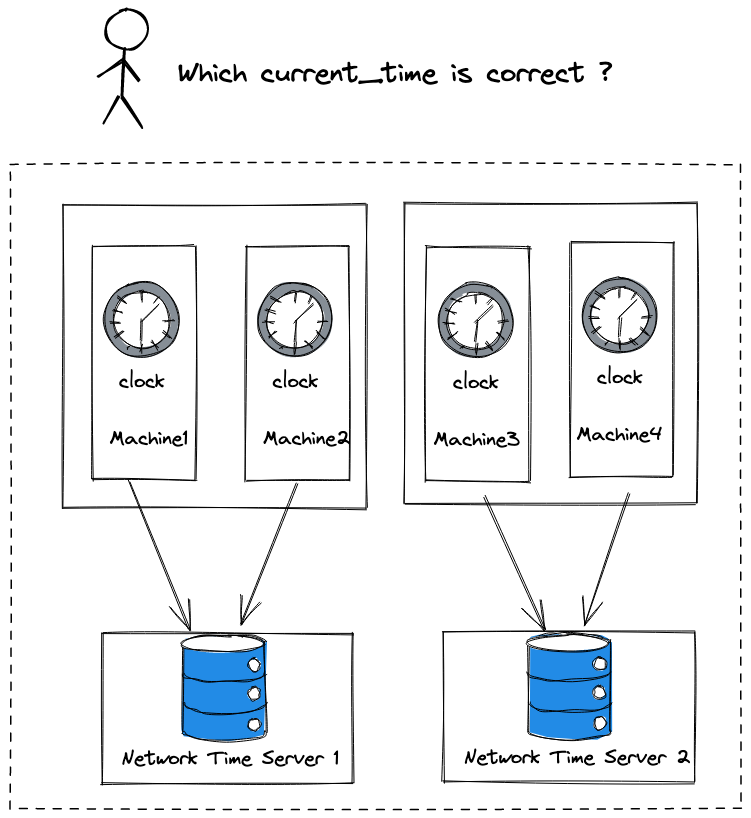
In order to get the correct time, it’s necessary to maintain a monotonic global clock(Of course, it’s not the only way to go, there are several ways to handle time and order). Since everything we care about clock is Unix timestamp, we could maintain a global system clock represented by Unix timestamp. All machines request the global clock every second to get the current time, fetching the expiry tasks later.
Well, are we done? Not yet, a new issue breaks into our design: if all machines can fetch the expiry tasks, these tasks will be processed more than one time, which will cause essential problems. We also need a mutex lock to guarantee only one machine can fetch the expiry task. You can implement both global clock and mutex lock by a magnificent strategy: an Optimistic lock
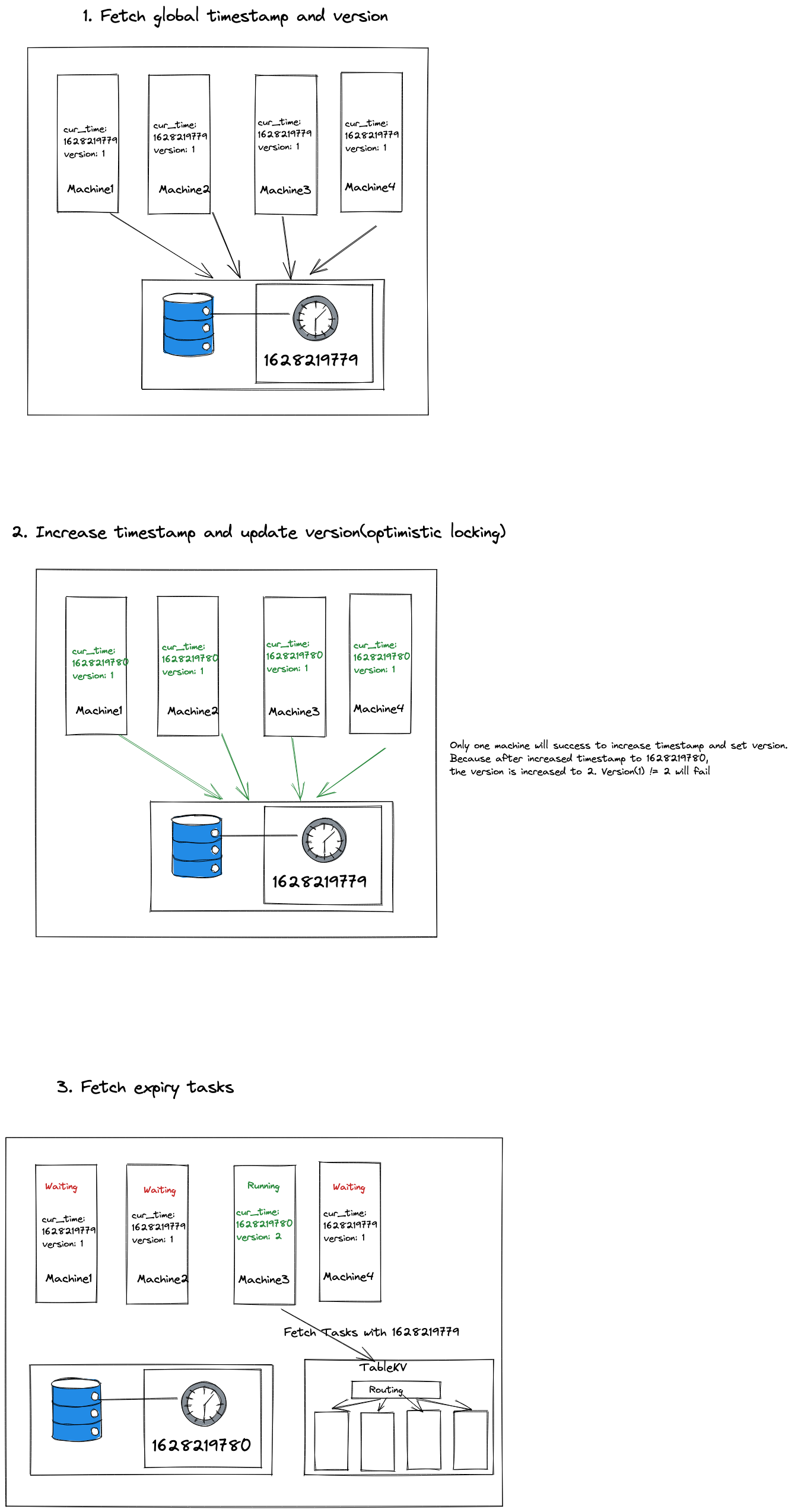
- All machines fetch global timestamp(timestamp A) with version
- All machines increase timestamp(timestamp B) and update version(optimistic locking), only one machine will success because of optimistic locking.
- Then the machine acquired mutex is authorized to fetch expiry tasks with timestamp A, the other machines failed to acquire mutex is suspended to wait for 1 seconds.
- Loop back to step 1 with timestamp B.
We could encapsulate the role who keep acquiring lock and fetch expiry data as an individual component named scheduler.
2.4 Expiry processing
Expiry processing is responsible for invoked the user-supplied callback or other user requested action. In distributed computing, it’s common to execute a procedure by RPC(Remote Procedure Call). In our case, A RPC request is executed when timer task is expiry, from timer service to callback service. Thus, the caller(user) needs to explicitly tell the timer, which service should I execute with what kind of parameters data while the timer task is triggered.
We could pack and serialize this meta information and parameters data into binary data, and send it to the timer. When pulling data out from slot, the timer could reconstruct Request/Response/Client type and set it with user-defined data, the next step is a piece of cake, just executing it without saying.
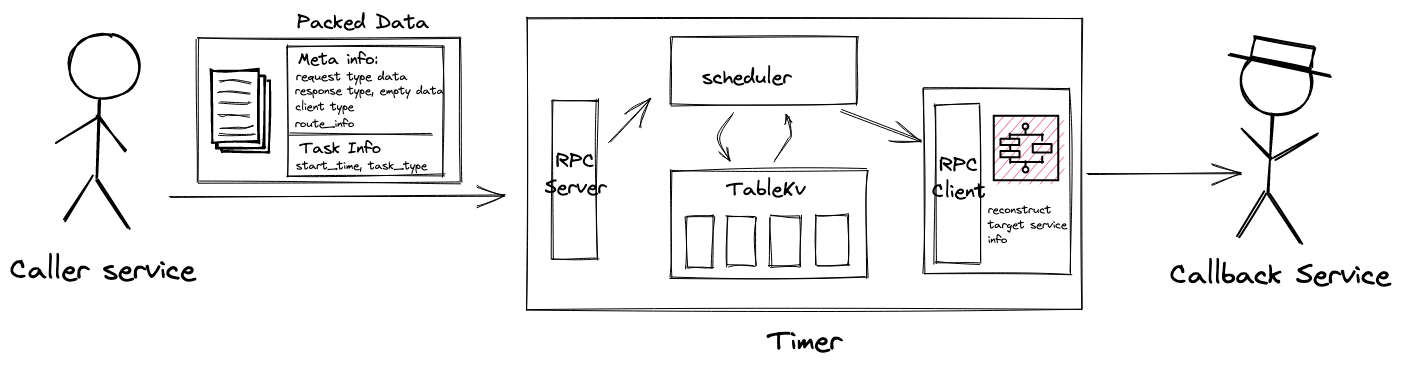
Perhaps there are many expiry tasks needed to triggered, in order to handle as many tasks as possible, you could create a thread pool, process pool, coroutine pool to execute RPC concurrently.
2.5 Decoupling
Supposing the callback service needs tons of operation, it takes a hundred of millisecond. Even though you have created a thread/process/coroutine pool to handle the timer task, it will inevitably hang, resulting in the decrease of throughout.

As for this heavyweight processing case, Message Queue is a great answer. Message queues can significantly simplify coding of decoupled services, while improving performance, reliability and scalability. It’s common to combine message queues with Pub/Sub messaging design pattern, timer could publish task data as message, and timer subscribes the same topic of message, using message queue as a buffer. Then in subscriber, the RPC client executes to request for callback service.
After introducing message queue, we could outline the state machine of timer task:
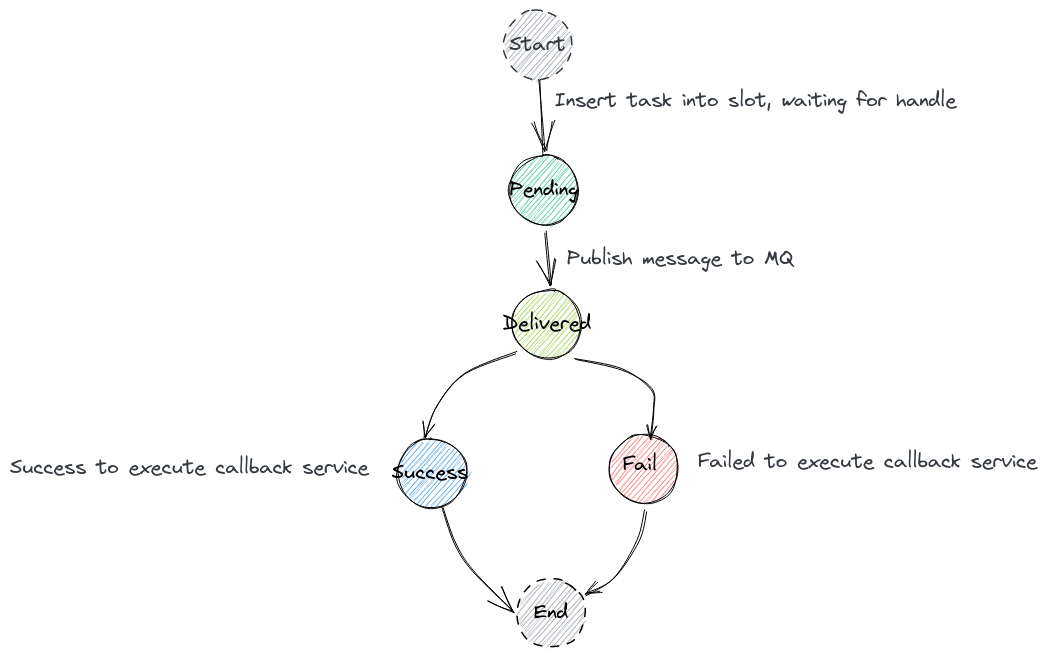
Thanks to message queue, we are able to buffer, to retry or to batch work, and to smooth spiky workloads
2.6 High availability guarantee
2.6.1 Missed expiry tasks
A missed expiry of tasks may occur because of the scheduler process being shutdown or being crashed, or because of other unknown problems. One important job is how to locate these missed tasks and re-execute them. Since we are using global `current_timestamp` to fetch expiry data, we could have another scheduler to use `delay_10min_timestamp` to fetch missed expiry data.
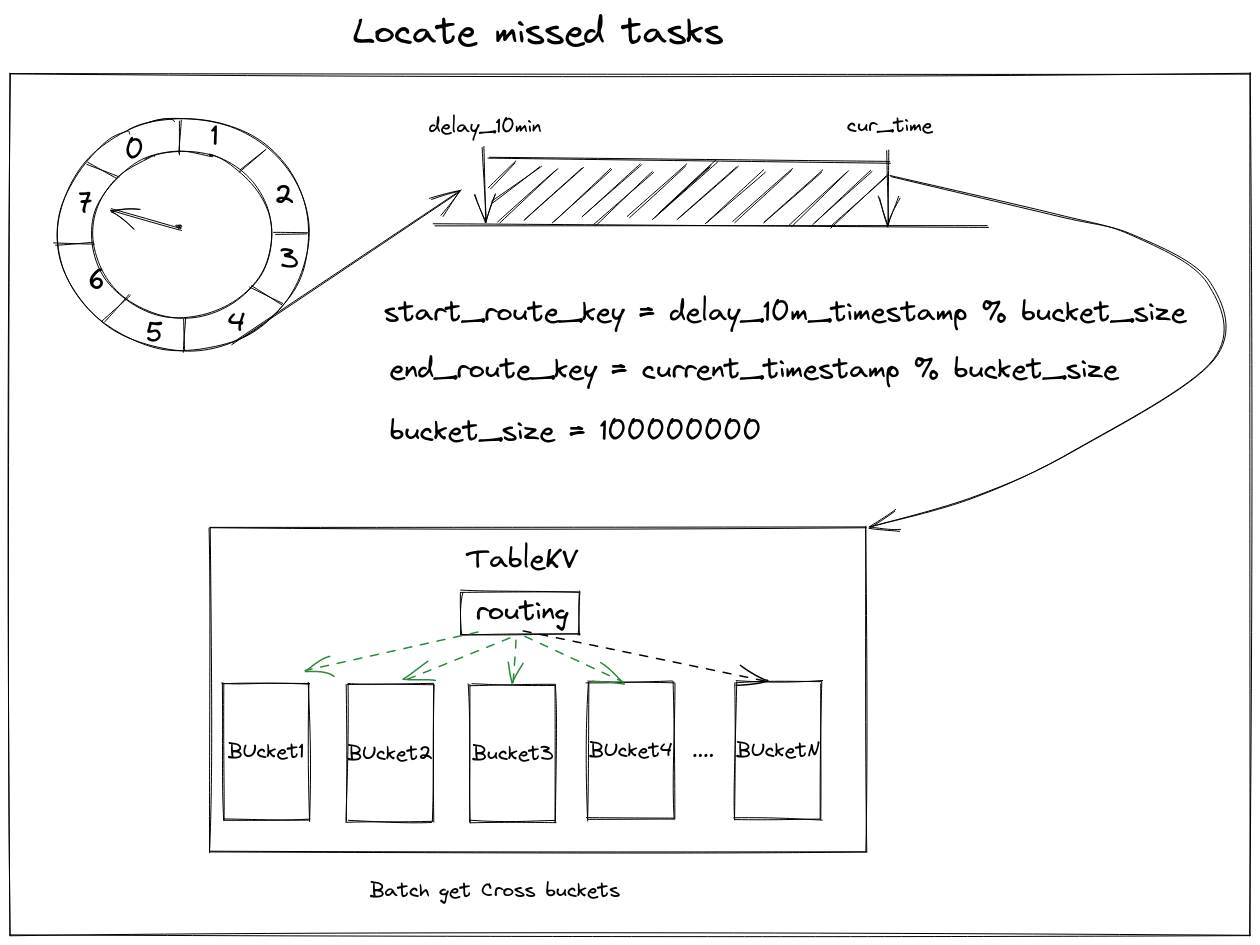
In order to look for a needle in a haystack, we need to set a range(delay_10min - current time), and then to batch find cross buckets. After finding these missed tasks, the timer publishes them as a message to message queue. For other open source distributed timer projects like Quartz, which provides an instruction to handle missed(misfire) tasks: Misfire instructions
If your NoSql component doesn’t support find-cross-buckets feature, you could also find every bucket in the range one by one.
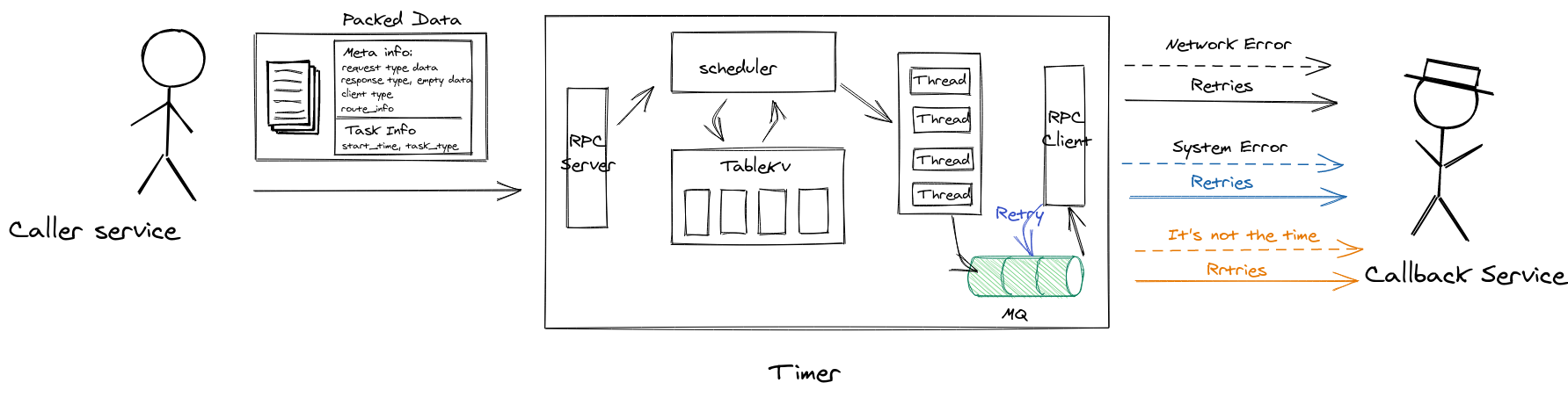
2.6.2 Callback service error
Since the distributed systems are shared-nothing systems, they communicate via message passing through a network(asynchronously or synchronously), but the network is unreliable. When invoking the user-supplied callback, the RPC request might fail if the network is cut off for a while or the callback service is temporarily down.
Retries are a technique that helps us deal with transient errors, i.e. errors that are temporary and are likely to disappear soon. Retries help us achieve resiliency by allowing the system to send a request repeatedly until it gets an explicit response(success or fail). By leveraging message queue, you obtain the ability for retrying for free. In the meanwhile, the timer could handle the user-requested retries: It’s not the proper time to execute callback service, retry it later.
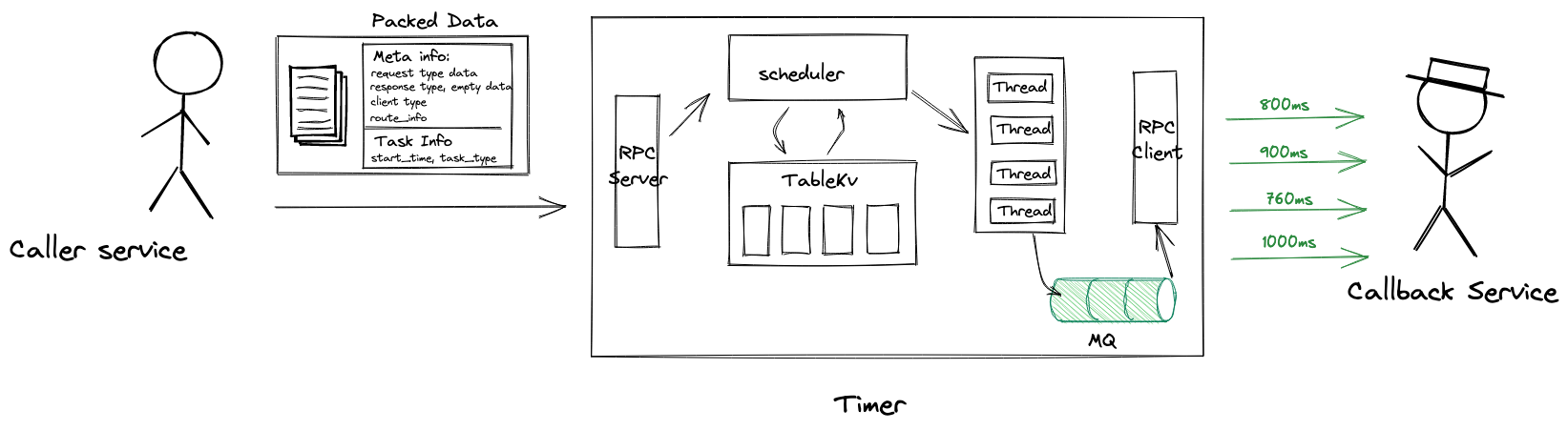
3 Conclusion
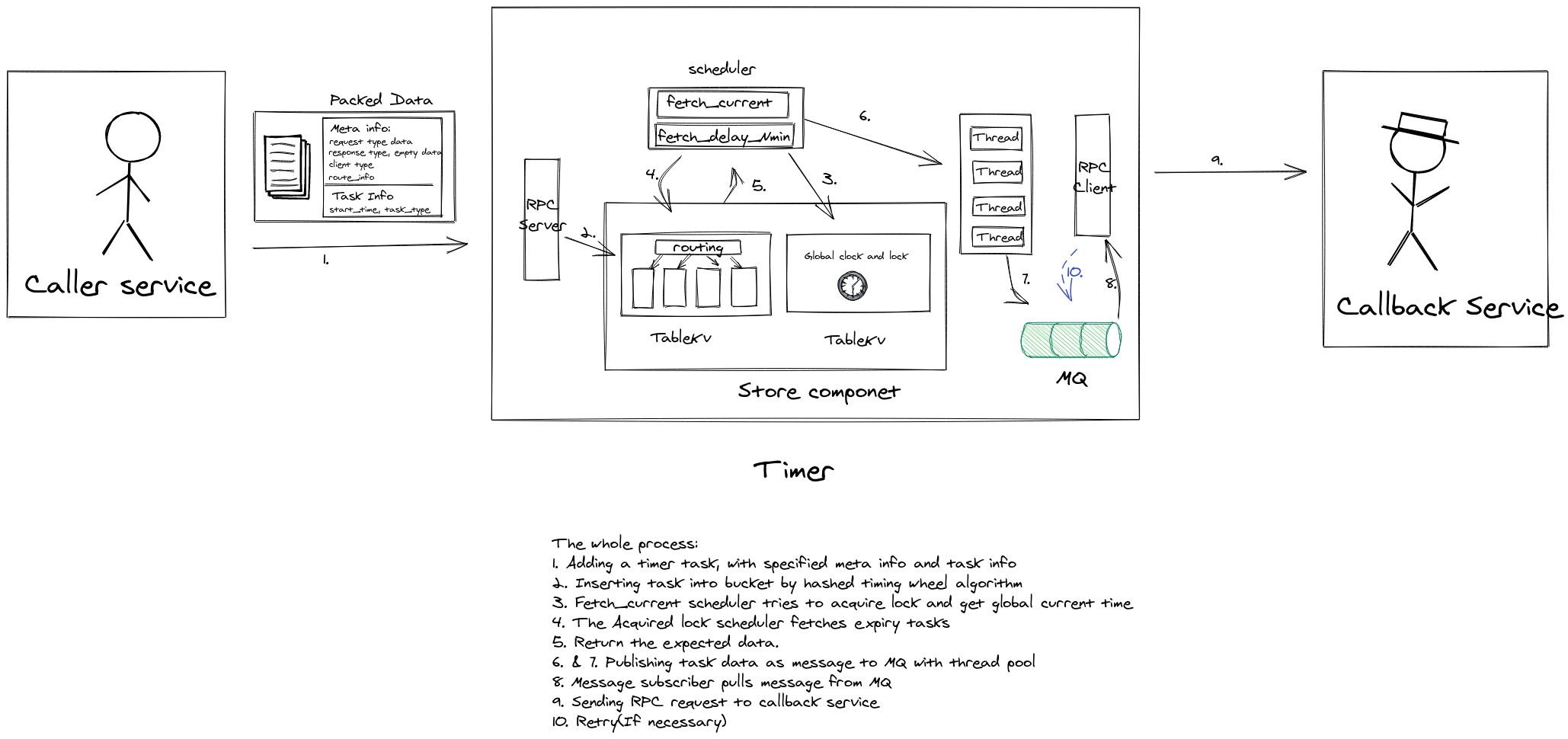
After a long way, we are finally here. The final full architecture would look like this:
The whole process:
- Adding a timer task, with specified meta info and task info
- Inserting task into bucket by hashed timing wheel algorithm(With
task_stateset topending) - Fetch_current scheduler tries to acquire lock and get global current time
- The Acquired lock scheduler fetches expiry tasks
- Return the expected data.
- & 7. Publishing task data as message to MQ with thread pool; And then set
task_statetodelivered - Message subscriber pulls message from MQ
- Sending RPC request to callback service(set
task_statetosuccessorfail) - Retry(If necessary)
Wish you have fun and profit